Introduzione alle funzioni del markup
La semantica di una parola è caratterizzata dalla mia scelta (design sul significato). Non mi dice molto, quindi proviamo a raccontare qualcosa in più.
Definiamo markup ogni mezzo per rendere esplicita una particolare interpretazione di un testo.
In particolare è un modo per esplicitare qualche significato. (un po’ come la punteggiatura, che da qualche altra informazione oltre le singole parole, rende più chiaro l’uso del testo).
Le informazioni aggiuntive possono essere riguardanti:
- La struttura del testo
- La formattazione del testo
- Relazioni fra parti del testo.
Tipologie di Markup (6)
Puntuazionale
Questo è un markup che l’autore stesso dà. ed è fortemente ambiguo!.
Il markup puntuazionale consiste nell’usare un insieme prefissato di segni per fornire informazioni perlopiù sintattiche sul testo.
Presentazionale
Effetti grafici per comunicare fine capitolo o altri simili

Procedurale
Questo è una tipologia di markup che utilizza delle istruzioni per definire la presentazione. (quindi in questa parte ci sono dei comandi!) (esempi credo siano latex o Tex)
Descrittivo
Vuole descrivere la struttura e la semantica di frammenti di testo. (non è procedurale, perché non gli dico pezzo per pezzo la grafica), io dico se è un testo, se è una didascalia, in modo simile a quanto fatto qui su Notion.
Referenziale
Quando faccio riferimento a cose esterne per risolvere il significato. Di solito fa usi di SIGLE o abbreviazioni di qualcosa
MetaMarkup
Se utilizzo un linguaggio per creare un linguaggi di Markup, un esempio è Word, perché con quello utilizzo il linguaggio di markup (descrittivo, su font e simili), anche HTML.
Metamarkup consiste nel fornire regole di interpretazione del markup e permette di estendere o controllare il significato del markup.
Metodi di classificazione di markup
- Standard privato oppure pubblico
- Se è interno o esterno (nel senso se si riferisce al testo interno oppure al testo esterno)
- binario o leggibile (per dire se è più fruibile per le macchine oppure se è fatto per essere fruibile per esseri umani)
- Poi si fa anche una distinzione fra procedurale (latex o troff like) oppure dichiarativi, nel senso che si taggano parti per indicarne l’utilizzo (come pe rl’HTML).
Alcuni linguaggi di Markup
Groff, Troff and NROFF
Questi sono scritti i linguaggi di markup per i manuali tecnici di Linux.
Tex and LaTeX
Software di impaginazione autoomatica, principalmente per formule matematiche, perché ci metteva troppo a fare il suo libro che la casa editrice sbagliava le formule. C’è anche un metafont utilizzato per astrarre la fomra dei caratteri… È poi turing completo, molto difficile, moltissime keyword. È molto difficile quindi Leslie Lamport crea una libreria molto più facile da utilizzare.
Markdown
Una semplificazione molto semplice, con formattazioni ad hoc, utili per testi semplici, senza molta possibilità di avere cose tipografiche precise.
JSON and YAML
Introduction to JSON
JSON (JavaScript Object Notation) is a data format designed to facilitate data exchange over the internet.
From a Big Data perspective, it is a very common format for storing data in a denormalized way (see Database Normalization). It can operate without adhering to strict data integrity rules without any issue.
JSON data is often referred to as semi-structured data because it can be easily processed by both machines and humans, whereas traditional databases are typically machine-readable only, and plain text is primarily human-readable (though this distinction may be changing).
YAML, which has a Python-like structure, uses indentation (spaces) as delimiters. It is a superset of JSON, meaning it can also parse JSON. Other than this, YAML is similar to JSON but has the added feature of supporting comments.
Well-formedness
JSON and other Markups have standardized syntaxes, also called languages in theoretical computer science, because they have some specific syntactical rules which specify whether if a string is well-formed or not (note that this is different from validation!). These data formats are important in the context of Big Data as they allow to store data in denormalized form for fast reads. We explained in Relational Model how we can mathematically model relational databases, we can also simply map them to key-values, as we do with JSONs! JSON documents can start with an object or array, the two composite datatypes.
JSON datatypes
JSONs have 6 datatypes:
- strings
- As normal strings, but you can escape characters with a backslash.
- Numbers
- JSON places a few restrictions: a leading + is not allowed. Also, a leading 0 is not allowed except if the integer part is exactly 0 (in which case it is even mandatory, i.e., .23 is not a well-formed SON number literal)
- null
- objects
- keys must be quoted strings
- keys should not be repeated
- arrays
- boolean We will skip examples of these types, but you need to know what type is what for the exam.
SGML
SGML (Standard Generalized Markup Language) è uno standard di IBM rilasciato gratis. SGML è un meta-linguaggio non proprietario di markup descrittivo. Facilita markup leggibili, generici, strutturali, gerarchici.
This is just historical remark, you can skip this without any problem.
È una tipologia di markup chiara, leggibile, strutturata, descrittiva e gerarchica, i primi fisici erano molto felici per questo metalinguaggio di markup.
Struttura di un documento SGML
- Dichiarazione SGML
- DOCTYPE, o dichiarazione dei nomi utilizzabili all’interno del documento
- Istanza del documento
-
Slide

-
Esempio SGML

È uno dei Markup più importanti perché possiamo dire che sia il precursore dell’HTML
Costituenti base di SGML
-
Elementi

-
Attributi

-
Entità

-
PCDATA

-
Commenti

-
Processing instructions

Questa parte dovrebbe essere molto importante se si parla della parte teorica, però nella pratica mi sembra che siano in verità utilizzate pochissimo, sono comuqnue interessanti sapere che esistano
XML
XML (eXtensible Markup Language) is a quite mature W3C standard. Many things in industry need to be formatted in XML format, even if it seems JSON seem to be more popular. Technically JSON and XML are the same, but XML is just a little more mature. It is very similar to #HTML, but that is for webpages (browsers are lot more lenient when parsing HTML), and XML is for data, they have two divergent stories, even if the starting syntax is similar.
XML is used in tax collection in Switzerland, or in publishing industry for books for example. È un sottoinsieme di SGML, che ha molte più garanzie formali. (infatti se definita con BNF è abbastanza difficile da comprendere).
The XML information Set
The XML Information Set is a formal, tree-based abstraction of an XML document as defined by the World Wide Web Consortium (W3C). It breaks down an XML document into “information items”, for example:
- Elements (tags)
- Attributes of the elements
- Textsj They have different rules of nesting, we will see it in the next section.
Below, is a wider discussion on information items.
-
Document Information Item: This is the root of the information set for an XML document and represents the entire document. It includes properties like children (the top-level elements of the document) and optionally the document type declaration.
-
Element Information Items: These represent XML elements in the document. Each element information item has properties such as:
- Local name and namespace: The name of the element and the namespace it belongs to.
- Children: Other element information items or character information items (text nodes) that are contained within the element.
- Attributes: A set of attribute information items associated with the element.
- Parent: The parent information item (either another element or the document).
-
Attribute Information Items: These represent the attributes of elements. Key properties include:
- Local name and namespace: The name of the attribute and the namespace it belongs to.
- Normalized value: The value of the attribute after normalization (processing character references and entities).
- Owner Element: The element information item to which the attribute belongs.
-
Character Information Items: These represent the text within elements. They consist of a sequence of characters, also called text
-
Other Information Items: Depending on the XML document, there can be other types of information items, such as comments, processing instructions, and namespaces, though these are not always included in every XML document’s information se
Abbiamo detto che XML è un sotto-formato di SGML, ed è utilizzato principalmente per fare una verifica formale che tutti i tags dichiarati siano a validi e cose simili.
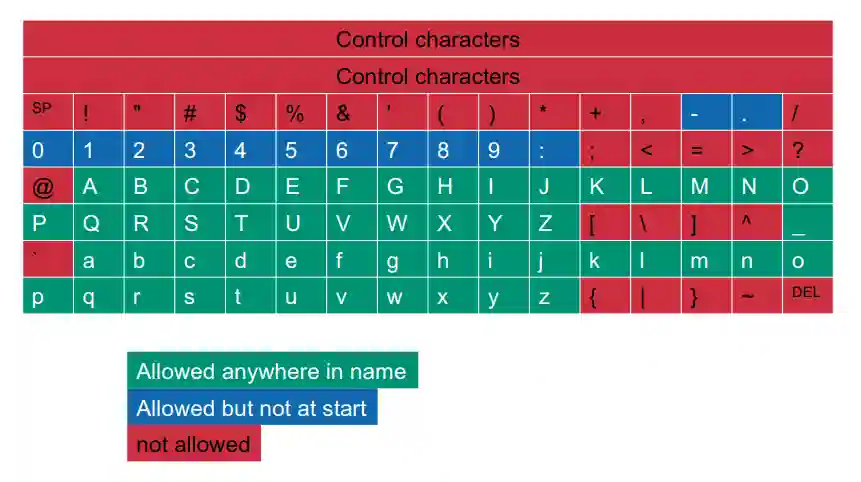
Valid XML Elements
XML elements are not free to have whatever character in the utf-8 charset, they have some rules:
- They cannot start with a number or “:”, “-”, “.”
- They cannot start with xml (reserved for the XML standard)
- They cannot contain spaces
- They cannot contain special characters (Only _ are allowed everywhere).
Well-Formed XML

We have a few rules about XML:
- Tags should be well nested (you can only nest between open and closed tags, not in the middle)
- There should be no < and closing > in the attribute or quotation marks or somewhere else, they should be escaped
- There should be a single root element
- Attributes cannot be in the top level, and should be between quotation marks
- They should be different for a single tag (not same attribute repeated!)
- They cannot start with
xml, see namespaces later.
- Single elements can be closed with the following syntax
<empty/>. - Text can be only between element tags
- Entities should be defined (? did not understood this).
- It should start with the text declaration (defining the version and the encoding).
- DOCTYPE declaration is optional, it has the name of the top level element in it.
The table above summarizes valid XML formats.
Also the tags have some rules about possible characters:
Namespaces
This is the same idea as a module in python or namespace in C++. This prevents tags with the same name to conflict with each other.
To specify a namespace we add an attribute xmlns, usually in the top level element to keep things clean. These namespaces usually point to a URI resource (good practice is using a domain that you own as a namespace, and it’s this authority that decides what is this namespace for), which could be a website or something similar to that.
You can use default namespaces, or use QNames and define a name for that namespace, you use a syntax like xmnls:name and then prepend name:tag to every tag.
