Introduzione alla normalizzazione
Perché si normalizza?
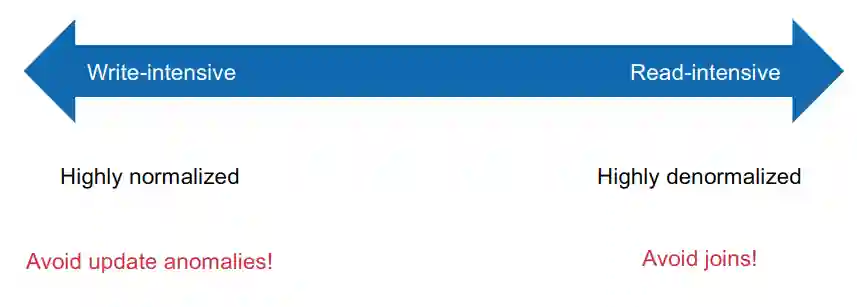
Cercare di aumentare la qualità del nostro database, perché praticamente andiamo a risolvere delle anomalie possibili al nostro interno, e questo aiuta per la qualità. Solitamente queste anomalie sono interessanti per sistemi write intensive, in cui vogliamo mantenere i nostri dati in una forma buona. Però capita non raramente che vogliamo solamente leggere. In quei casi sistemi come Cloud Storage, Distributed file systems potrebbero risultare più effettivi.
Tipologie di anomalie
- Ridondanze, non vorrei avere la stessa informazione espressa più volte in troppi punti.
- Update non consistente, quando per aggiornare un singolo valore devo aggiornare moltissime altre tuple dipendenti da essa.
- Deletion non consistente, la presenza di certe entità è strettamente dipendente da presenza di altri, nell'esempio in questione sulle slides, se elimino tutti gli utenti, elimino anche i progetti su cui hanno partecipato, mentre invece dovrebbero essere separati.
- Insertion, ad esempio se non posso inserire un certa entry finché una altra proprietà legata (ma per il resto indipendente non è stata definita, nell'esempio del prof provare ad inserire un lavoratore, ma senza progetto.)
Ci possono essere molte forme di non-normalizzazione per i database. La figura seguente riassume il concetto (preso da qui).
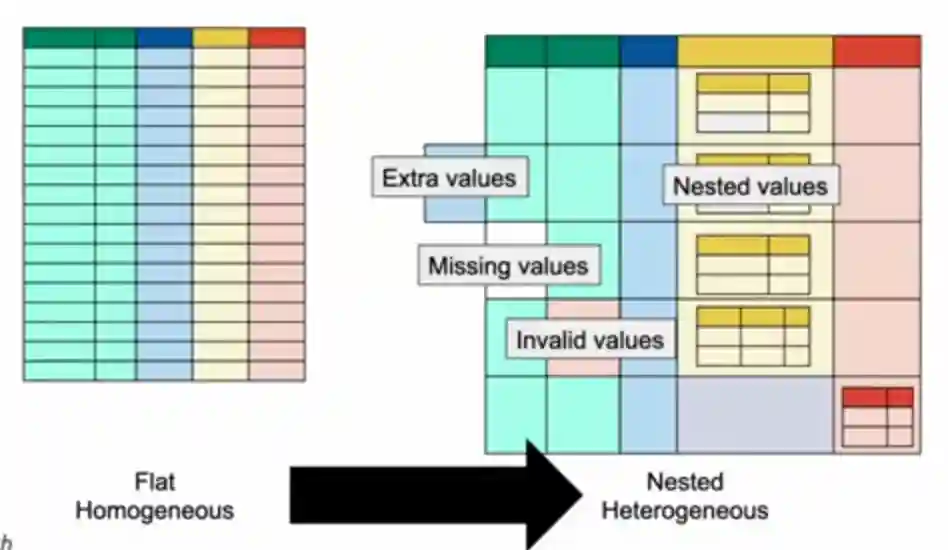
Forme di integrità
- Integrità atomica: ogni cella deve avere un singolo valore, non può avere delle tavole innestate e non ci devono essere righe ripetute (ridondanze).
- Integrità di dominio: ogni valore della cella deve possedere valori che appartengono al dominio della colonna.
- Integrità relazionale: Foreign key values must either be NULL or match an existing value in the referenced table’s primary key.
Dipendenze funzionali
Vogliamo cercare di identificare le dipendenze funzionali e separarle, questo aiuta a creare qualità nel database La dipendenza funzionale è un vincolo di integrità speciale, simile a quello relazionale spiegato in Relational Model
Definizione formale di dipendenza funzionale
Data una relazione sullo schema due sottoinsiemi non vuoti di attributi e sono detti funzionalmente dipendenti per ogni coppia di tuple e in con stessi valori per tutti gli attributi in abbiamo che questi hanno gli stessi valori anche su .
Osservazioni:
- Funzione, perché in un certo senso il primo insieme è il dominio, e il secondo è il codominio, ed è come se ci fosse una funzione che li associ.
- Esistono dipendenze funzionali banali quelli il cui il secondo insieme di attributi è un sottoinsieme del primo.
- Dipendenza funzionale con chiave essendo unica, non abbiamo duplicati di chiave, quindi l'implica implicito nella definizione ha sempre l'ipotesi falsa, quindi è sempre vero (guarda logica per capire il senso della mia frase).
Livelli di normalizzazione
Definizione formale Boyce e Codd (!)
Una relazione si dice in forma normale di Boyce e Codd se per ogni dipendenza funzionale non banale definita sulla relazione, contiene una chiave di , cioè è una super-chiave di
Questa il professor Ghislayn lo chiama anche forma normale 3.5 Ossia vogliamo solamente dipendenza funzionali tramite chiavi, e non in altro modo, altrimenti probabilmente avrò una ripetizione. Per esempio, con questa forma normale non sono accettate parti di chiavi che dipendono da altre chiavi, mentre con la terza forma normale questo era tollerato.
L'idea principale è che una tavola fa una singola cosa e niente altro.
Prima forma normale
Questo è la stessa cosa delle integrità atomica.
Seconda forma normale
Possiede la prima forma normale e deve essere che ogni colonna non chiave deve essere dipendente dall'intera chiave, e non una sotto parte. Altrimenti possiamo andare a denormalizzare.
Definizione terza forma normale
È una forma leggermente più rilassata, utile per normalizzare anche quando BC non è possibile fare.
Una relazione è in terza forma normale se per ogni dipendenza funzionale non banale vengono verificate una delle due condizioni:
- ha una chiave di
- Ogni attributo di appartiene ad almeno una chiave di
Il primo dovrebbe corrispondere a Boyce Codd. Il secondo credo sia nuovo, possiamo dire quindi che sia una estensione, che permette la definizione di normalizzazione essere applicata a più cose. Questa decomposizione è sempre possibile, abbiamo un teorema che lo dice.
Intuitivamente, possiamo dire che è in terza forma normale se è in seconda e non ci sono dipendenze funzionali fra le non chiavi stesse, altrimenti possiamo scomporre ancora.
La pagina Wikipedia asserisce questo requisito:
tutti gli attributi non-chiave dipendono soltanto dalla chiave, ovvero non esistono dipendenze funzionali tra attributi non-chiave.
Che è molto più semplice da ricordare, e in un certo senso simile a Boyce-Codd.
Nel contesto di NoSQL
NoSQL va a rilassare questi constraints, per questo motivo abbiamo
- Data eterogeneo (no tabulare)
- Nested data (no prima forma normale)
- Data denomalizzato (non abbiamo boyce Codd o altra forma normalizzata)
not having to join brings a significant performance improvement in reads
Questo è uno dei motivi per cui i dati sono solitamente non normalizzati nei big data attuali.
Metodi di normalizzazione
Decomposizione senza perdita
Sia dato un insieme di attributi e una decomposizione, non partizione, in e , abbiamo che la relazione si decompone senza perdita su e quando la join delle due è uguale a . ossia:
Questa è una necessità per ricostruire le informazioni iniziali senza nessuna perdita. Si può notare che talvolta seguendo in modo cielo le dipendenze funzionali che si possono trovare seguendo una via di Boyce and Codd, non è sufficiente per mantenere questa proprietà tanto importante.
Prendiamo un esempio con perdita (perché vado a ricostruire un esempio con più informazioni):
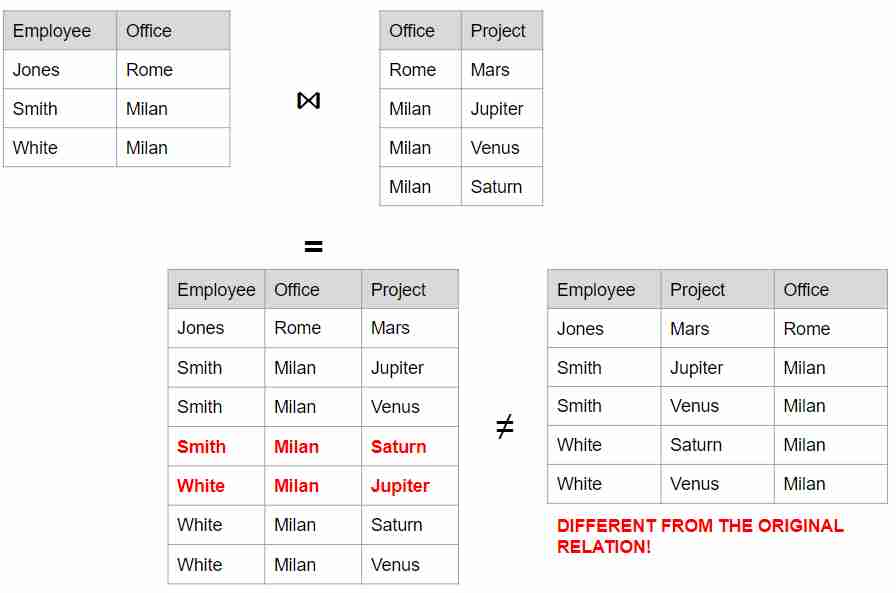
Questa non è una cosa che vogliamo!
Un modo per risolvere questo è aggiungere degli attributi fittizi che ci aiutano a discriminare sulle cose che ci servono. Ci fanno da specie di chiave.
Conservazione delle dipendenze
Questo permette di mantenere i vincoli di integrità.
Una decomposizione preserva la dipendenza se ogni dipendenza funzionale dello schema originale ha attributi che compaiono nello stesso schema, altrimenti non è possibile rilevare le dipendenze funzionali (Atzeni, pagina 332)
Cioè se spezzo una dipendenza funzionale in tavole diverse, questa proprietà non viene soddisfatta, perché non sarei più in grado di trackarlo.
Prendiamo un esempio in cui questa caratteristica si dimostra utile
Normalizzazione nello schema concettuale
Possiamo utilizzare questa idea anche nella parte di sviluppo di schemi E-R. Se riconosco a questo livello che c'è una dipendenza funzionale, questo mi da indicazioni su come continuare lo sviluppo di questo. Nell'esempio sulle slides motiva un partizionamento verticale, vedi Database logical design.