Object Stores
Characteristics of Cloud Systems
Object storage design principles
We don't want the hierarchy that is common in Filesystems, so we need to simplify that and have these four principles:
- Black-box objects
- Flat and global key-value model (trivial model, easy to access, without the need to trasverse a file hierarchy).
- Flexible metadata
- Commodity hardware (the battery idea of Tesla until 2017).
Object storage usages
Object storage are useful to store things that are usually read-intensive. Some examples are
- Static websites
- Images, Videos or video chunks
- Big files that are usually only to read (e.g. datasets).
Service Level Agreements (4)
We will talk now about Service Level Agreements which are important to understand the contract part of using cloud services. So, if a company does not satisfy these requirements, one can sue them for breach of contract.
-
Scalability We have 100 buckets per account that could be extended on request.
-
Durability We lose 1 in a objects during a year (which is 99.999999999% of durability), which is quite strong (so there is still a possibility that the object is lost). This is useful for the lawyers because they can offer a guarantee. If this is not respected then people can sue them.
-
Availability We have an availability of 99.99% which means maximum of 1h for a year. Usually it's useful to remember the percentages of availability:
99% 4 days/year
99.9% 9 hours/year
99.99% 53 minutes/year
99.999% 6 minutes/year
99.9999% 32 seconds/year
99.99999% 4 seconds/year
- Response time Legally it's hard to guarantee average speeds, so what they do is actually count the times where the service is guaranteed to be below a certain threshold! So they guarantee that in of the cases they have a response lower than , in other cases its higher. However, as it is usually difficult to satisfy a latency requirements which is often geographically dependent answer, S3 offers guarantees based on system throughput, which is how many reads and writes it can handle without any problem.
Replication types
Replication can be synchronous or asynchronous or other two types based on where (update everywhere or just a primary copy):
In summary we have:
| Method | Advantages | Disadvantages |
|---|---|---|
| Synchronous | - No inconsistencies (identical copies) - Reading the local copy yields the most up-to-date value - Changes are atomic | - A transaction has to update all sites (longer execution time, worse response time) |
| Asynchronous | - A transaction is always local (good response time) | - Data inconsistencies - A local read does not always return the most up-to-date value - changes to all copies are not guaranteed - Replication is not transparent |
| Update everywhere | - Any site can run a transaction - Load is evenly distributed | - Copies need to be synchronized |
| Primary Copy | - No inter-site synchronization is necessary (it takes place at the primary copy -> fast) - There is always one site which has all the updates | - The load at the primary copy can be quite large - Reading the local copy may not yield the most up-to-date value |
Synchronous Replication
Synchronous replication propagates any changes to the data immediately to all existing copies. Typically done in the context of transactions: the changes are propagated within the scope of the transaction making the changes. The ACID properties apply to all copy updates.
The above is usually done by database management systems.
Asynchronous replication
Asynchronous replication first executes the updating transaction on the local copy. Then the changes are propagated to all other copies. While the propagation takes place, the copies are inconsistent (they have different values). -> eventual consistency
It is faster! In systems where the consistency is not of utmost importance, this is a good thing. The following two subsections are two versions of types of replication (independent ways).
Update everywhere
With an update everywhere approach, changes can be initiated at any of the copies. That is, any of the sites which owns a copy can update the value of the data item.
This can be a sign of some inconsistencies that need to be solved. Others are quorum based (like the #Key-value stores.)
Primary Copy
With an update everywhere approach, changes can be initiated at any of the copies. That is, any of the sites which owns a copy can update the value of the data item.
Amazon S3
Amazon used to sell books, then they started to rent cloud services because they had too many machines that most of the time they were not using. This was a big win from an economical point of view. They created amazon web services. Now they are selling these abstractions: Amazon S3 stands for simple storage service.
S3 Document Identification
With S3 every document is identified by a bucket id and a object id, which could be maximum 5 TB (probably physical constraints of the file), it is only possible to upload an object in a single chunk if it is less than 5 GB. The buckets can uniquely identify that in the world. The maximum amount of buckets that a user can have is 100 by default, while the maximum number of objects is unlimited, they can handle billions of objects without problems.
We don't know how S3 works underneath, they have not published it.
Storage Classes
The cost of the storage service changes with the frequency of the access. For example
- Amazon Glacier has a very high latency (hours to get the files), but its cost is quite low. This should be used for example for backups! With these applications we don't care if the answer is in seconds. Hours is fine.
- Standard with infrequent access: we have a cost of retrieving, with less availability
- Standard: it's just the standard S3 structure.
Accessing a resource
We use Uniform Resource Identifier to identify the resource we want to access, and the usually send a REST request to modify, delete or get it.
This is an example of a S3 bucket http://bucket.s3.amazonaws.com/object-name (if you want to access the bucket, just remove the object identifier!).
We can have operations like PUT, GET, DELETE for Buckets and objects.
Usage Examples
Most common usage of buckets is storing read intensive data, like static websites or dataset shards (which then become useful for systems like MapReduce or Spark). The performance is nice, the professor reports about 300ms for the website to load. Usually you can see a hierarchy on the UI for such systems, but that is just for interface, under the hood, we just have a flat key-value store.
It is common to place a content delivery network (CDN) service on top of the storage bucket of a website in order to accelerate and cache these files at multiple places on the planet.
Azure Blob Storage
In this section we will describe the service provided by Azure cloud on cloud storage.
To store seemingly limitless amounts of data for any duration of time and pay only what is being used. WAS provides cloud storage in the form of Blobs (user files), Tables (structured storage) and Queues (message delivery). WAS claims to satisfy strong consistency, high availability and partition tolerance all at the same time; ie. all of CAP.
Azure Document Identification
Azure blob storage needs 3 id to identify a document:
- Account
- Container (bucket equivalent), which is sometimes called partition in literature.
- Blob (document id equivalent) 195 GB for an Append Blob to 190.7 TB for a Block Blob. The maximum storage size is different!
Location Service
Withing Azure, there are three main regions: US, Europe, and Asia, each one of these has at least a datacenter with multiple storage stamps and one or more building. This is used to optimize the latency of the service. Each one of this has the so called Location Service which handles:
- Storage stamps monitoring (managing)
- Account namespace across all stamps
- Allocation of accounts to storage stamps and monitoring for disaster recovery.
- Load balancing across storage stamps.
- Itself is distributed across regions for disaster recovery.
Location Service manages all the storage stamps and the account names- pace and assignment of accounts across the stamps. Itself distributed and redun- dant, performs disaster recovery and load balancing by updating DNS entries to the respective exposed VIPs (Virtual IP) of the assigned stamp.
Fabric Controller
The Windows Azure Fabric Controller is a resource provisioning and management layer that provides resource allocation, deployment/upgrade, and management for cloud services on the Windows Azure platform.
It has a role similar to the ResourceManager in Yarn, see Massive Parallel Processing.
Stream Layer
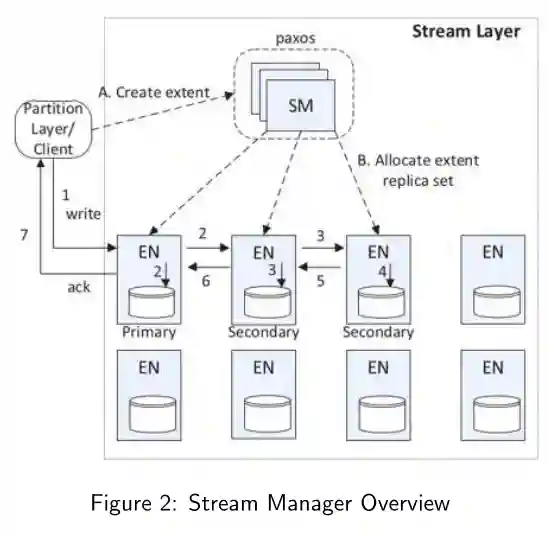
Partition Layer
The partition layer is made of two main components:
The partition manager Responsible for keeping track of and splitting the massive Object Tables into RangePartitions and assigning each RangePartition to a Partition Server to serve access to the objects.
A partition server is responsible for serving requests to a set of RangePartitions assigned to it by the PM.
This is somewhat similar to what is done in Wide Column Storage for region servers.
Object APIs
And we can divide the files into blocks which support a higher size.
- Blocks are for data. Maximum size of 50k 4GB blocks, about 190.7 TB.
- Append are for logs because they are optimized to append stuff, of maximum size of 195 GB. Which corresponds to 50k 4MB blocks.
- Page are for in memory virtual machines maximum size of 8 terabytes.
Stamps
Azure Blob Storage is organized into the so called storage stamps. These stamps are 10-20 racks with 18 storage nodes each (maximum storage for a stamp is about 30PB of data). Usually kept below 80% data (if not they'll have a warning), else they could buy more storage or move data elsewhere.
Replication (2)
They have two types of replications:
- Intra-stamp: which is synchronous way of replicating (immediately replicated).
- Inter-stamp: asynchronously replicating to other stamps.
Regions (2)
As with AWS, they have regions to optimize for latency and be resistant to natural catastrophes. The latency part is intuitive: if a data center is physically closer to you, then it's more probable that the data will be served faster. Natural catastrophes are mitigated by having the data in different regions, so if one is destroyed, then the data is still safe.
Key-value stores
S3 is far more slower than typical database systems to store and query the data. In the order of hundreds of 100ms against 1-9ms for key-value stores. So two orders of difference! Too high latency for some uses!.
Key value stores (aka associative arrays, we use map data structure) solve this problem and can be adapted to be used as a database system, the cost is that the type of objects we can store is far smaller, in the order of few hundreds of kilobytes.
These are quite often used for intermediary caches, another example of an application that uses key-value stores is memcached.
Characteristics of Key-value stores
This is designed for performance and scalability, but it gives up consistency for eventual consistency. This is usually a simpler version, but it doesn't have the same features as more complex data storage systems, as relational database management systems.
Usually these are used for shopping carts for a very large online shop, another is for storing likes and comments on social media
Design principles of Key-value stores (4)
-
Incremental stability New nodes can join the system at any time, and nodes can leave the system at any time, sometimes gracefully, sometimes in a sudden crash. But we don't need to have too many nodes to crash, which is not the scope of our course.
-
Symmetry No node is particular in any way, the nodes are similar to one and another. They run the same code.
-
Decentralization There is no leader or orchestrator in the network. Note that symmetric protocols could elect a leader nonetheless, while in this case we have the strict requirement not to have a leader.
-
Heterogeneity the nodes may have different CPU power, amounts of memory, etc.
Comparison With ObjectStorage
Limitations compared to S3 and Azure Blob Storage
Yet, this brings some drawbacks: We have the values to be far smaller, about 400kb of data (this is what Dynamo does) and we cannot store metadata It has a simplified APIs that just supports get, put or delete the document, with a given key or value (in reality there is also a context variable). This is why they are often more suitable for real-time data, simplicity and speed.
What are Contexes?
These values are the state of the updates for every node, this is used to merge the vector clocks in case of need. Providing a context to get or put, allows the key-value store to correctly update the context so that later in case of partitions, it could be exactly solved.
Common Usage Patterns
Particular usages are for example shopping carts, likes and comments on social media, and so on.
One of the typical use cases for a key-value store is storing shopping carts for a very large online shop, another is for storing likes and comments on social media.
best seller lists, shopping carts, customer preferences, session management, sales rank, and product catalog, from (DeCandia et al. 2007).
Chord protocol
The amazon paper (DeCandia et al. 2007) describes this system.
This is based on a distributed hashing protocol. We use hashes because they have some properties to be robust against failures of some kind, which I have not understood.
With this protocol, every node has an ID. For example a code in (Dynamo indeed uses 128 bytes). If we have a key this is assigned to a position on the ring. Then from this position we follow the ring clockwise until we find a node, this node should handle the value of this key.
Consistent Hashing
The ring structure of the Chord protocol is called consistent hashing. It has been designed to minimize the amount of transfer of data in distributed systems that join and leave frequently. See Tabelle di hash for a primer of how hashing works.
Other systems use this type of hashing, like the CassandraDB or CDN services. It acts as an automatic load balancing system.
The principle advantage of consistent hashing is that departure or arrival of a node only affects its immediate neighbors and other nodes remain unaffected.
Join, Leave and Crash
When a node joins, the should take the responsibility of part of the data in front of him in a clockwise fashion. When a node leaves, it should give responsibility of part of the data to the node in front of him. Clearly this is not possible when we have a crash, this is why we need redundancy, which is easily done by having 2-range redundancy, but it can be set to any value.
One thing that should be noted with the updates is how it handles the replication: only single node modifies, but after it propagates the update to the replicas and receives acks. Then you use vector clocks to choose the highest update number. A nice parallel with vector clocks is the parallel between these and the Newtonian physics vs Structure of spacetime and different timelines.
Reads on Dinamo
A client periodically picks a random Dynamo node and downloads its current view of Dynamo membership state. Using this information the client can determine which set of nodes form the preference list for any given key.
A preference list is just a map of each object and the node that is currently storing that object. With the classical Chord protocol the so called finger tables where used where you could employ binary search to find the node that is responsible for the key. With finger tables, each node knows what the following nodes to the power of two have, so that the search could be employed.
Every time a node wants to look up a key , it will pass the query to the closest successor or predecessor (depending on the finger table) of in its finger table (the "largest" one on the circle whose ID is smaller than ), until a node finds out the key is stored in its immediate successor.
Probably this approach has been dismissed because it is a little bit more burgeoning to update the finger table on joins or leaves, and preference lists are a better practical solution.
This is called the client driven approach, and from their tests, it seems twice as fast as the server driven approach.
Preference lists
This solves the problem of finding the actual node that has the data we are querying for. It is just a table with a key -> and nodes that have it. We have distributed algorithms that make the nodes agree on this preference list which is just knowing what machine is responsible for what interval range. For each key range, the first node on the list is called the coordinator node, it this fails, the random node that has gotten request attempt to contact every node until one answers. is the minimum number of nodes from which the value needs to be retrieved for it to be considered consistent. is the minimum number of nodes for which an ack should be received to consider it towards a successful read. We have the theoretical necessity that to set up a quorum system, whose acknowledgement is based on the majority of notes that have accepted a certain modification. Sometimes the system is also configured to values less than for a better latency, which is configurable by the developer.
Tuning the values for and scale the performance stability of reads and writes. For example read-intensive applications, would prefer to have and so that it is fast to read, but could potentially read some inconsistent data. The most common configuration is for Dynamo.
Advantages and disadvantages
Pros:
- Highly scalable
- Robust to failure (because we replicate data with the ones in front of us).
- Self-organizing. I don't know if the above properties are exclusive, but they are nice
Cons:
- Only lookup, no search (obvious)
- No data-integrity (we don't have a way to check for integrity constraints)
- Security issues (Need to understand this)
Virtual Nodes
Two problems arise with the Chord protocol: there could be large gaps in the Circle and the underlying machines could have different hardware proposals. The idea is to have some nodes take other nodes in a way proportional to its hardware. In this manner, if a node has more resources, it has more nodes, which implies it is expected to handle more data (which is fine because it has more resources).
CAP Theorem
Statement of CAP
We can only have two of the following properties:
- Consistency (doesn't depend on the machine that answers to your request).
- Availability (it should answer something).
- Partition tolerance (the system continues to function even if the network linking its machines is occasionally partitioned.)
We don't have ACID anymore (see Advanced SQL) in the case of Big Data. So now we have 3 possible scenarios, which correspond to the 3 couples that is possible to have with these properties.
For example, let's say we have a partition of the network then we have two cases: not available until the network is connected again, but we still have the same data. Or we have two parts that answer differently (this is usually called eventual consistency, because after the network is connected then it will return to the consistent state), but are still available to the users.
When network partitions happen we need to choose what property we want to keep, so we have three possible cases: CP, CA or AP. Services like Dynamo Key value store (see Cloud Storage#Key-value stores) choose AP and thus have eventual consistency.
Vector Clocks
Sometimes when we have a network partition we lose the linear timing of the system and so we have directed acyclic graphs

Example of a DAG due to network partition
The merge happens in the following manner: just choose the maximum value for each resource that has been modified. This grants consistency, but could lose some data.
PACELC Theorem
PACELC is a generalization of the CAP theorem. The acronym PACELC stands for:
- P: Partition tolerance (as in the CAP theorem).
- A: Availability.
- C: Consistency.
- E: Else.
- L: Latency.
- C: Consistency.
PACELC integrates the latency in normal running cases. We can tradeoff between being low latency but accepting some inconsistencies, or being consistent with a little higher latency.
Cloud Databases
Original databases usually do not work well on the cloud, since they've been optimized to assume the classical disk read seeks. These kinds of databases usually display too much communication overhead.
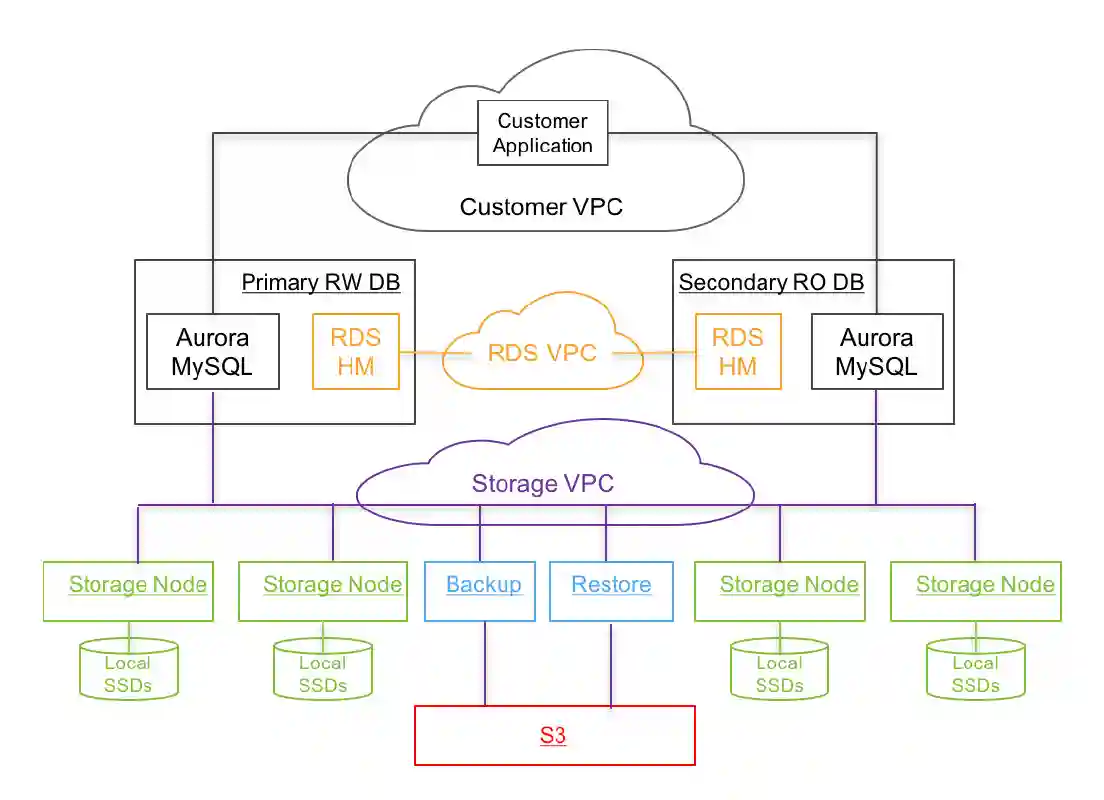
AWS Aurora
Innovations of the Aurora Service
Aurora database modifies MySQL databases to work in the cloud:
- Separate storage and cache management from transaction processing
- Primary copy, asynchronous replication
- designed for high performance, scalability, and availability.
Mainly used for OLTP workloads (See Data Cubes).
It provides 6 copies in 3 different zones. Updates with a quorum based and uses a primary copy structure with 15 read only replicas.
Aurora's architecture
It is able to scale automatically from 10GB to 128 TB.
Snowflake
Main objective is to separate compute and storage. This layer provides the storage part. Snowflake is fully managed and optimized for cloud environments, meaning it is cloud-native.
Architectural Components
Snowflake has a unique multi-cluster shared data architecture, which separates storage, compute, and services (this is why it is also called cloud native, meaning it has been done to work on the cloud originally!). This provides better scalability and cost efficiency compared to traditional monolithic databases.
We list here three main layers:
- Storage Layer (Cloud Object Storage)
- Data is stored in an optimized columnar format in cloud storage (AWS S3, Azure Blob, or Google Cloud Storage).
- Snowflake automatically manages compression, encryption, and metadata.
- Allows Time Travel: meaning past versions of data can be accessed without manual snapshots.
- Compute Layer (Virtual Warehouses)
- Compute resources (called Virtual Warehouses) process queries.
- Each warehouse is isolated, meaning workloads won’t interfere with each other.
- Can auto-scale up or down based on query demand.
- Different warehouses can query the same data without duplicating storage.
- Cloud Services Layer
- Manages authentication, metadata, query optimization, and access control.
- Handles ACID transactions for consistency.
- Implements Query Caching at multiple levels to speed up performance.
Virtual warehouses
- A virtual warehouse is a collection of worker nodes (EC2 instances in Amazon)
- Each worker node has a cache in its local disk where it stores the objects (table files or parts there of) accessed before
- The cache uses a simple LRU replacement policy
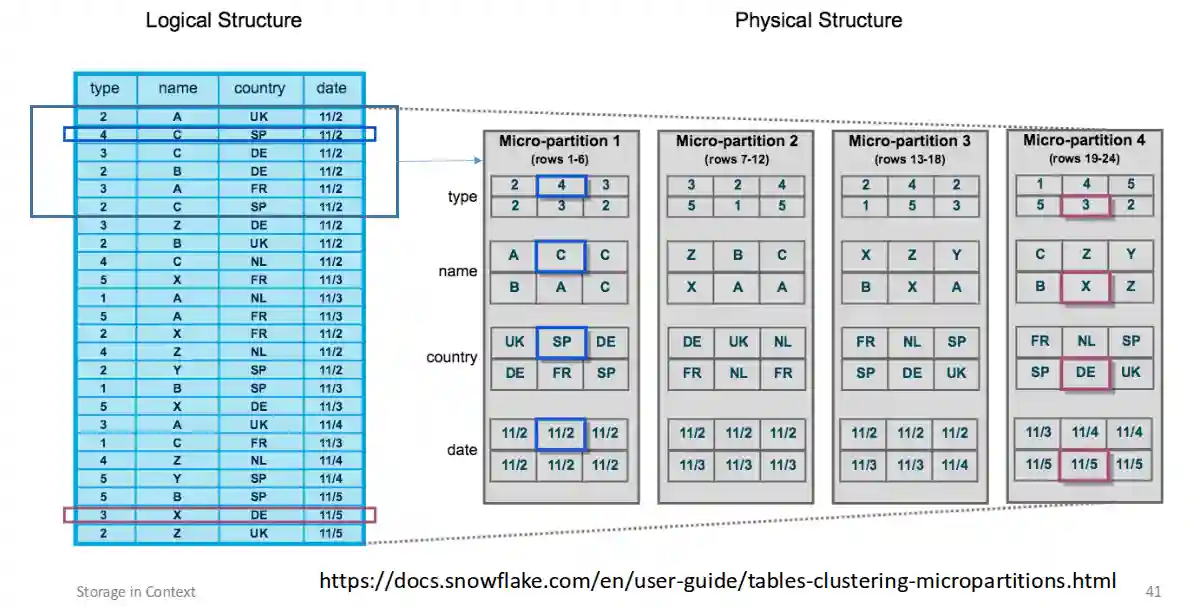
Micro partitions
This is how the tables are actually stored in these database (columnar fashion, more efficient in allocation an look up -> Data Models and Validation, Wide Column Storage).
We have columnar partition in a manner similar to what is done in Wide Column Storage, where the partitions were called regions.
Other Solutions
We consider here Redis and Memcached. Both are distributed in memory storage services that are quite good to serve read intensive workloads. However, Redis has many features, while memcached is just a key-value pair. This article compares redis with memcached:
References
[1] DeCandia et al. “Dynamo: Amazon's Highly Available Key-Value Store” ACM SIGOPS Operating Systems Review Vol. 41(6), pp. 205–220 2007