Introduzione all’algebra relazionale
Confronto con relazioni matematiche
Le relazioni come le intendiamo in database sono leggermente diverse rispetto a quelle presenti per le relazioni matematiche:
- Non conta l’ordine
- Ci sono gli attributi
Per il resto se introduciamo questo sistema per tenere conto delle astrazioni, possiamo analizzarle matematicamente, e questo ci fornisce qualche sicurezza in più diciamo.
Four types of operations
- Set operations: union, intersection, difference
- Filter queries: Projecting or selecting
- Renaming queries: renames
- Join: correlare tuple di relazioni diverse
Definition of tuples
Le relazioni sono esattamente quelle definite in matematica, però noi aggiungiamo anche gli attributi, in modo da poter considerare l’ordine delle colonne non importante.
Per prendere anche gli attributi possiamo definire così:
- Tupla = funzione che associa attributo (una stringa) a un valore del dominio dell’attributo, definito da una funzione esterna
- Relazione è un insieme di tuple. Facendo in questo modo ho risolto il problema dell’ordine
Set operations
Possiamo modellare l’algebra come se
Unions Intersections
Vengono indicati con i simboli classici presenti nella teoria degli insiemi $\cap ,\cup$ Questa parte non ho capito perché deve esistere… Che scopo ha?
Operazioni principali
Renaming
Sintassi e semantica
Questo è un operatore unario.
It produces changes on the schema that keep the underlying data un-altered
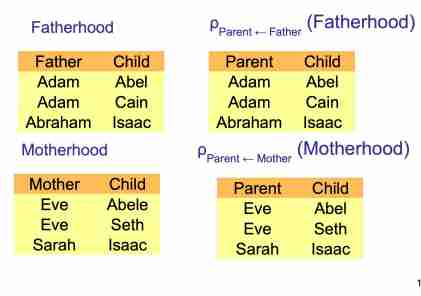 Da questa immagine è abbastanza intuitivo la sintassi utilizzata.
$$
\rho_{end \impliedby start} (table)
$$
**Semantica:** Un attributo del dataset viene richiamato con altro nome.
### Selection
Anche questo è un **operatore unario**.
#### Proprietà della selection (3)
1. Schema dell'output è lo stesso
2. L'output soddisfa un predicato (logico).
3. L'output è solamente un subset.
**Concatenazione**:
$$
\sigma_{a}(\sigma_{b}(R)) = \sigma_{a \land b }(R)
$$
$$
\sigma_{a}(R_{1}\cup R_{2}) = \sigma_{a}(R_{1}) \cup \sigma_{a}(R_{2})
$$$$
\sigma_{a}(R_{1} - R_{2}) = \sigma_{a}(R_{1}) - \sigma_{a}(R_{2})
$$
Da questa immagine è abbastanza intuitivo la sintassi utilizzata.
$$
\rho_{end \impliedby start} (table)
$$
**Semantica:** Un attributo del dataset viene richiamato con altro nome.
### Selection
Anche questo è un **operatore unario**.
#### Proprietà della selection (3)
1. Schema dell'output è lo stesso
2. L'output soddisfa un predicato (logico).
3. L'output è solamente un subset.
**Concatenazione**:
$$
\sigma_{a}(\sigma_{b}(R)) = \sigma_{a \land b }(R)
$$
$$
\sigma_{a}(R_{1}\cup R_{2}) = \sigma_{a}(R_{1}) \cup \sigma_{a}(R_{2})
$$$$
\sigma_{a}(R_{1} - R_{2}) = \sigma_{a}(R_{1}) - \sigma_{a}(R_{2})
$$Altro con insiemi
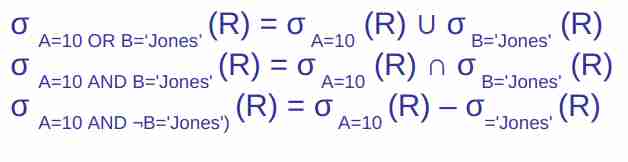 Possiamo notare che operano proprio come se fossero dei set, nel senso unione per or, intersezione per and, e anche intersezione col contrario con il meno.
Possiamo notare che operano proprio come se fossero dei set, nel senso unione per or, intersezione per and, e anche intersezione col contrario con il meno.
Sintassi e semantica
$$ \sigma_{predicate}(Relation) $$Semantica: un insieme che soddisfa le #Proprietà della selection
Projection
Anche questo è un unary operator.
Semantica e sintassi
$$ \pi_{attribute}(Relation) $$Semantica: viene ritornato un insieme con numero tuple della relazione iniziale (o minore per ripetizioni), ma solo con gli attributi di riferimento.
$$ \pi_{Y}(r) = \left\{ t[Y] | t \in r \right\} $$Ossia prendo i valori della tupla che corrispondono a quegli attributi, per ogni singola tupla presente in relazione
Caso ripetizioni
Questa è una cosa da notare, a differenza di Structured Query Language le cose ripetute vengono scartate, si ha unico, in questo caso, perché qui siamo nel reame degli insiemi
Proprietà di proiezioni
$$ \pi_{x}(R) = \pi_{x}(\pi_{xy}(R)) $$Se lo applico più volte (anche con cose leggermente diverse rimane uguale)
$$ \pi_{x}(R_{1} \cup R_{2}) = \pi_{x}(R_{1}) \cup \pi_{x}(R_{2}) $$Join
La join è necessaria nel caso vogliamo creare correlazione fra tuple presenti in relazioni diverse fra di loro, mentre con #Projection e #Selection possiamo farlo solamente sulla prima.
Full and empty joins
- Full -> Every tuple is used (not full is some is used)
- Empty -> with no outputs
Questo è direttamente dipendente da quali chiavi abbiamo usato durante la join ! 500
{kind=link}
Types of Joins (2)
$$ R_{1} \bowtie R_{2} = \left\{ t \text{ on } X_{1} \cup X_{2} | \exists t_{1} \in R_{1} \text{ and } \exists t_{2} \in R_{2} \text{ with } t[X_{1}] = t_{1} \text{ and } t[X_{2}] = t_{2}\right\} $$Ossia data una tupla nella nuova relazione così creata, se prendo i attributi appartenenti alla prima relazione avrò che esiste effettivamente uguale per il secondo.
Outer joins: Che sono le stesse spiegate in Structured Query Language, ossia andiamo a considerare left, right and full $A ⟕ B, A ⟖B , A⟗B$, sono i simboli utilizzati, ma userò sempre $\bowtie$ con pedice l, r, f per indicarne il tipo, per semplicità di notazione.
La semantica di questi è la stessa per SQL, la descriviamo prevemente, sarà left outer, nel caso in cui ho la garanzia che solamente le tuple della relazione 1 ci sarà, contrario per right, per il full outer, ho la garanzia che una data tupla finale, sarà presente in almeno uno dei due iniziali, ma non so quale.
Proprietà (2)
Push selection ! 500
$$ R \bowtie(R_{1} \cup R_{2}) = (R \bowtie R_{1}) \cup(R\bowtie R_{2}) $${kind=link}
Theta Join
Il theta join viene motivato grazie al fatto che solitamente bisogna sempre rinominare prima di fare una selection, o bisogna fare sempre selection, per questo motivo. Solo che questo è possibile fare solo se sono una #Cartesian product, ossia non abbiano attributi in comune.
La sintassi ammessa nella condizione sono solamente and e relazioni booleane binarie (minore, maggiore, uguale e combinazione fra questi). Altra cosa necesssaria per la theta join, è che non ci siano attributi in comune fra le due relazioni.
E si può notare sulle slides che questo è molto simile alla natural join dopo renaming espresso in #Types of Joins (2)) in precedenza.
Equi Join
Quello più interessante sono le equi-join che accade quando ho relazioni di equivalenza, questo si manifesta solamente quando la theta join di sopra è fatta da atomi di uguaglianza, questo mi dovrebbe garantire per certo tale proprietà.
Cartesian product
Si può considerare come una join naturale su relazioni senza attributi in comune (quindi tutto si può combinare con tutto!).
Views
Introduzione alle data-views
Sono delle rappresentazioni diverse dello stesso genere di data, solitamente utili per fare view diverse (e.g. dipartimento altro avrà necessità diverse), abbiamo accennato a questa necessità durante la nostra Introduction to databases.
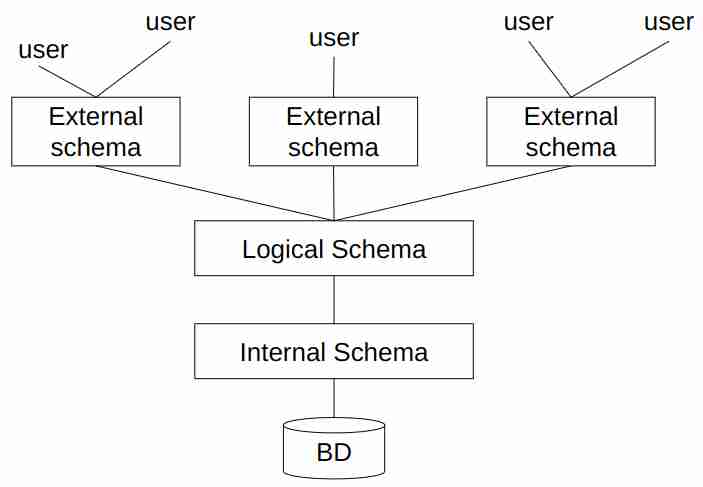
Nel caso preciso di SQL ne andiamo a parlare in Advanced SQL.
Nel caso di algebra relazionale, è soltanto una specie di dichiarazione di variabile con un altro nome, che specifica quale è il risultato della sua query.
View utilization
Questa è una cosa classica in informatica, il concetto di astrazione implementazione presente come descritto in Astrazione sul controllo#Significato di astrazione E dividere in questo modo quello che è effettivamente memorizzato da quello che l’utente deve volere vedere.
Materialized views
La differenza con l’altra tipologia di view che viene proposta è che questa view è storata fisicamente sui dispositivi di memorizzazione.
Pros:
- Veloce da leggere (non da creare ogni volta)
Cons:
- Ridondanza dei dati
- update deve essere doppio (problemi di coerenza)
- Non supportati dai DBMS.
Virtual views
Al fine di creare la view viene fatto una query sul database. Non so esattamente se questi possono essere fatti sempre o meno.
View update
Nel caso di sql possiamo andare a definire due valori local o cascade, con il primo la view non aggiorna le tabelle effettivamente presenti, mentre con cascade sì. Ma credo non si possa sempre fare e bisogna sempre stare leggermente attenti.
Some notes on update difficulties
È molto più difficile updatare la view, perché questo update deve essere coerente con la versione originale che era esistente! Per questo motivo non tutti gli update sono disponibili per update.
Relational calculi
Si differenzia leggermente dall’al
Introduction to relational calculi
Alla fine si basano tutti su Logica del Primo ordine, Questo è sempre un modo per modellare le relazioni che sono molto comuni nei casi che abbiamo trovato di relational databases, ma invece di utilizzare algebra utilizzano una logica, descritta sotto.
Questo è molto più vicino all’approccio logico, sviluppato durante gli anni 70-80 con knowledge bases in AI.
General form
$$ \left\{ A_{1}: x_{1}, \dots A_{k} : x_{k} | f \right\} $$In cui abbiamo
- $f$ che è una formula che probabilmente da un booleano per decidere se prenderlo o meno.
- $A_{i}$ che sono degli attributi
- $x_{i}$ che sono delle variabili Avremo come output una tupla di $(x_{1}, \dots x_{n})$ che soddisfano $f$
Esempi:

Esistono forme anche leggermente più complicate, ma dobbiamo introdurre gli esistenziali:

Esistono anche i de morgan rules che si possono applicare, perché in pratica è logica.
Relational calculi, considerations
Aspetti negativi (2)
- Moltissime variabili inutili (troppo verboso scriverci).
- Presenza di espressioni senza senso e dipendenti dal dominio questo significa che se cambiamo il dominio di definizione cambiamo anche i valori che sono possibilmente denotati (non ho capito perché questa dovrebbe essere una caratteristica negativa poi).
Per risolvere il primo problema si aggiunge una sintassi più compatta, presentata come “range declaration syntax” (ma non è espressivo quanto algebra, in qualche modo si dimostra)…
Range declaration syntax
 Pagina 78 del libro ne parla meglio, dovrei approfondire quello.
#### Indipendenza da dominio
$$
A_{1} : x_{1} | not R(A_{1} : x_{1})
$$
Pagina 78 del libro ne parla meglio, dovrei approfondire quello.
#### Indipendenza da dominio
$$
A_{1} : x_{1} | not R(A_{1} : x_{1})
$$È dipendente dal dominio, perché prende l’insieme degli elementi nel dominio, tali che non sono presenti nella relazione. Abbiamo bisogno di questa proprietà perché se è dipendente dal dominio si potrebbero produrre risultati enormi, che rendono l’applicazione pratica nulla.
Equivalenza con Algebra relazionale
Si può dimostrare che se ci limitiamo alle espressioni indipendenti col dominio, i due modelli sono esattamente uguali, ossia possiamo dire che possiamo creare una espressione di algebra, partendo da calcolo, e viceversa.
La dimostrazione (che non facciamo) andrà per induzione strutturale, quella che trovi in Logica in Deduzione naturale.
Possiamo notare che l’algebra è indipendente dal dominio, perché lì non è mai esplicitata la relazione in che dominio sia (abbiamo operazioni chiuse si può dire).