Little bits of history
It was invented in 1970 in Almaden (San Jose) by IBM (Don Chamberlin, Raymond Boyce worked on this) for the first relational database, called system R. Then for copyright issues it hasn’t been called SEQUEL, so they branded it as SQL.
SQL is a declarative language
With declaratives language there is a separation between what I call the intentionality and the actual process. In declarative languages we just say what we want the result to be, and don’t care what the actual implementation is like. This allows queries to be executed and optimized in different ways, even if the query on the surface is the same
SQL is a functional language
SQL is also a functional language, because the main principle is based on expression evaluation. This allows SQL to have some nested expressions in it.
Data types
Default data types
I tipi di dati sono
- Carattere
- numero
- data
- tempo
- intervallo di tempo
- booleano
- blob (binario)
- clob (carattere)
Setting custom data types
Ma possono essere definiti anche tipi di dati custom, la sintassi è simile
CREATE DOMAIN Grade
AS SMALLINT DEFAULT NULL
CHECK (value >= 18 AND value <= 30)
Altering existing domains
In cui posso mettere anche dei check custom.
DROP DOMAIN
Per cancellare il domain lì presente
E si può anche cambiare con
ALTER DOMAIN
Posso aggiungere o eliminare constraints per esempio.
Però a seguito di questo comando, dovrei essere in grado di modificare correttamente i valori con schema cambiato, metterli a default, o metterli a null diciamo.
Data definitions
Database
Creation
CREATE DATABASE db_name, che va a creare un database che può contenere molte tavole, schemi diversi e simili.
Schema
È una descrizione logica di come è strutturato l’intero database, non è da confondere con lo schema di una singola tavola.
Schema creation
Lo schema è la specificazione dei domini e delle restrizioni che ogni colonna deve avere per essere integra. In più possono essere definite view diverse o anche authorization.
CREATE SCHEMA schema_name
Table
La tavola specifica una relazione vuota, che può seguire o meno uno schema, come definito di sopra.
Create table
!500
{kind=link}
Table constraints
Durante la creazione di una table posso specificare cose come
- Tipo (intero, carattere?)
- Valore di default
- Constraints (tipo NOT NULL)
- Reference esterna o chiave di tavola.
Deletion and change
Abbiamo comandi come
DROP TABLE
ALTER TABLE
Per eliminare o cambiare lo schema della singola table.
Solitamente posso modificare singole colonne per sql, aggiungere constraints o dati di default.
Referential trigger
Per le foreign keys posso andare a definire anche una
- Azione che viene eseguito quanto l’altra tabella viene
- Aggiornata
- Eliminata
- Azioni permesse sulla table con foreign key
- Cascade (eliminare o aggiornare di conseguenza)
- Set null
- set default
- no op, che non permette di fare l’operazione nemmeno sulla tavola originaria.
Indexes
Sono delle strutture di dati che permettono di svolgere certe operazioni in modo più efficiente, cercheremo di distinguere i casi in cui è effettivamente utile andare a creare questo indice. Questo solitamente è fatto al livello fisico.
CREATE INDEX idx_surname
ON officer (Surname)
Creo un indice con nome, su un attributo della table.
Data operations
CRUD:
- Create -> Insert
- Read -> SELECT
- Update -> UPDATE
- Delete -> DELETE (molto rischioso!)
Select
Le operazioni di select è molto simile a proiezione e selezione che sono trattati in Relational Algebra.
Sintassi classica
SELECT attributes
FROM tables and joins
[WHERE condition]
[GROUP BY attributes]
[HAVING conditions]
[ORDER BY attributes]
Compare: algebra relazionale
Si possono considerare molte similitudini in Relational Algebra
- Select and projection $\pi_{age, height}(\sigma_{age < 30}(people))$
- Select with renaming (projection)
- Pure select $\sigma_{age<30}(People)$
- Projection without selection $\pi_{age, height}(people)$ che prende colonne.
Da questo si può notare che SELECT da sola gestisce tre relazioni
- Select
- Projection
- Rename
Che sono stati trattati nell’algebra relazionale.
Possono anche essere estesi ad avere le
JOINusando cose del from.
Si potrebbe semplificare affermando
- WHERE = Selection in algebra relazionale
- SELECT = projection
- FROM = prodotto cartesiano.
Esempio complesso di query con Cartesian product e renaming ! 500
{kind=link}
Like and null values
Like è utilizzato per fare pattern matching sulla stringa. ! 300 Mentre i null values si possono gestire con sintassi $AGE\, is \, NULL$
{kind=link}
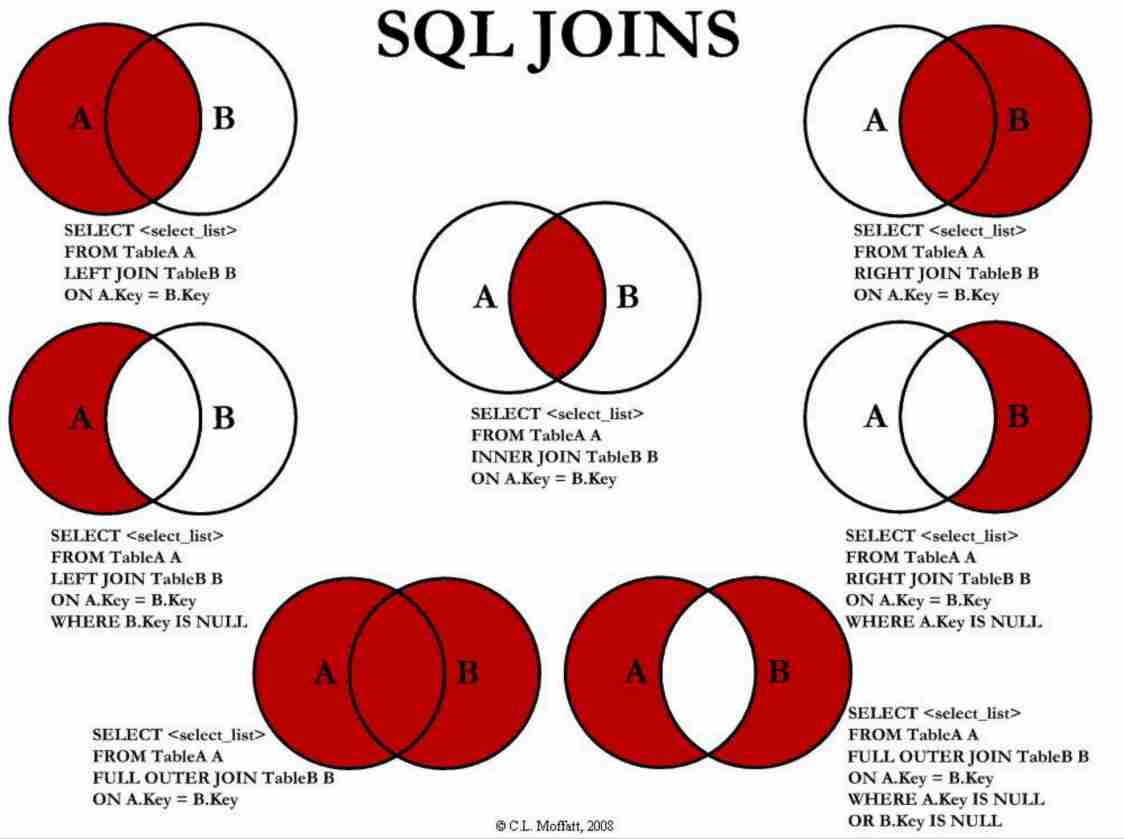
Join
Sintassi
precedentemente nella sezione #Select abbiamo utilizzato join delle tables in maniera implicita utilizzando il prodotto cartesiano. Esiste però anche una istruzione esplicita per dire che vogliamo fare JOIN, molto coerente con la teoria presente in Relational Algebra.
SELECT ...
FROM leftTable [JOIN rightTable ON condition]
[WHERE predicate]
 Esempio di differenza fra JOIN e il prodotto cartesiano con la sintassi di sopra.
Esempio di differenza fra JOIN e il prodotto cartesiano con la sintassi di sopra.
Inner and outer joins
La differenza principale fra inner e outer join è
- Inner Dati che non hanno elementi in comune vengono scartati (come quello presente sulla slides di sopra) questo viene anche chiamato natural join.
- Outer Vengono tenuti anche i dati che non fanno matching in una parte in comune, solitamente questi sono sempre chiamati left o right, ma vedremo dopo esattamente quale sia la semantica
LEFT: (right è esattamente il contrario) Ritorna sempre il sinistro, ma il destro può anche essere null FULL: ritorna sinistro se c’è e destro se c’è.
Remaining CRUD operations
La sintassi di insertion, deletion and update è molto più semplice rispetto alla lettura, quindi la mettiamo nella sottosezione.
Insert
NOTE: è importante l’ordine di inserimento!
INSERT INTO table [attrs]
VALUES(vals) | SELECT roba..
! 500
{kind=link}
Update
UPDATE TableName
SET Attribute =
< Expression, select, null or similar >
WHERE <cond>
Esempi:

Delete
DELETE FROM table
[WHERE condition]
 ### Altre Istruzioni
#### Sorting
Per fare sorting basta aggiungere **ORDER BY**
Order by può essere ascendente o discendente (facile se è alfanumerica come attributo).
DEFAULT: descending.
### Altre Istruzioni
#### Sorting
Per fare sorting basta aggiungere **ORDER BY**
Order by può essere ascendente o discendente (facile se è alfanumerica come attributo).
DEFAULT: descending.
Union intersection and difference
UNIONE
- Uso normale: come in figura
- Nel caso venga definito ALL, anche se è doppio, viene mantenuto.
- Nel caso di conflitti semantici, utilizzare positional notation, se sono nella stessa posizione vengono messi assieme (il nome dell’attributo è sempre della prima tavola) ! 500
{kind=link}
DIFFERENZA Si usa except, e poi altre notazioni sono simil ial precedente.
INTERSEZIONE Si usa intersect come istruzione. (ma è meglio usare il where, descritto in #Select, che è equivalente).
Intersection
Nested Queries
NOTA: ogni subquery viene eseguita ogni volta per
Correctness conditions
Le queries innestate vengono eseguite per ogni tupla esterna, e sono corrette se quanto viene ritornato è coerente con l’input del secondo
SELECT Name, Income
FROM People
WHERE Name IN
(SELECT Father FROM Fatherhood, People WHERE Child=Name AND Income>20)
In questo caso IN si aspetta poi un insieme, che è quanto ritornato nella subquery, il vantaggio principale di questo approccio è la leggibilità,
Visibilità
Ci sono due note riguardo la visibilità, perché seguendo una logica simile agli scopes strutturali se sono in scope esterno non posso accedere a quello internamente definito. Mentre la query innestata può leggere variabili definite esternamente. Chiaramente se hai due nested diverse, non riescono ad avere stesso variabile, segui le stesse regole di scoping definito in linguaggi di programmazione.
Existance
Exists
 Molto intuitivo, se sai un po' di Logica del Primo ordine.
#### Any and ALL
Sono altri predicati possibili per cose innestate
Molto intuitivo, se sai un po' di Logica del Primo ordine.
#### Any and ALL
Sono altri predicati possibili per cose innestate
Aggregate functions
Gli aggregate consentono di ritornare un valore unico da una lista di dati. Hanno una semantica precisa: Prima fatto tutto, ignorando dell’esistenza del groupby, fanno una selezione di tutti gli attributi che sono presenti qui, e poi effettivamente raggruppano. Sul libro atzeni è descritto in pagina 123. L’aspetto principale da ricordare è che attributi in group by sono superset degli attributi di selezione.
Classical sintax
La sintassi classica per questo genere di query è
Aggr([DISTINCT] attribute)
Attribute è il dominio su cui andare a runnare la funzione di aggregazione.
Some aggregate functions
Count
Ritorna semplicemente il numero di elementi dentro la lista

- Caso interessante da ricordare è count NULL values
AVG, MAX, MIN
Sintassi è uguale al precedente, poi la semantica è un po’ diversa, ma credo sia chiara dal nome delal fuznione aggregate
Grouping
La sintassi classica è
GROUP BY attributeList.
Semantica
- Prima esegue la query normale, come se grouping non esistesse.
- Poi esegue il grouping, e se c’è un aggregate function, eseguirlo sul singolo gruppo. Questa cosa è molto importante da conoscere perché altrimenti sbagli al query e questo mi era successo in passato, ci ho speso molto tempo. Giustifica anche il motivo per cui devi fare select dell’attributo di cui vuoi fare grouping, altrimenti non hai niente da grouppare diciamo!
NOTA: aggregate è eseguito sul singolo gruppo!
Other conditions
Si può usare HAVING per aggiungere altre condizioni sui gruppi in modo simile a quanto faceva WHERE dentro #Select.
Comportamento con i NULLs
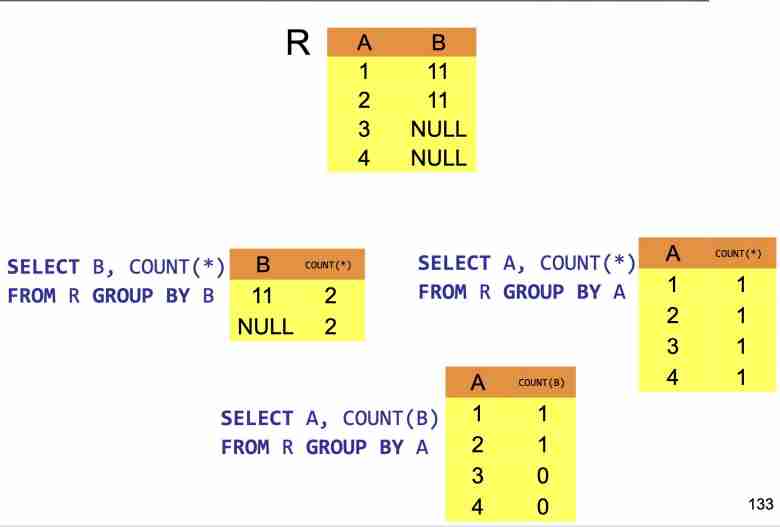
Altro
Sull’esecuzione di SQL
- È il DBMS che si occupa di eseguire la query ed ottimizzarla.
- Avere query corrette e leggibili è più importante.
- Questo descrive anche il perché sarebbe a volte sensato farle innestate.