Il suo scopo principale è gestire l’avvicendamento dei processi. Ad esempio sospendere il processo che chiede I/O. O un sistema time sharing, quando arriva un interrupt sul time.
Solitamente il nome scheduler è solamente un gestore dell’avvicendamento, si può quindi utilizzare per indicare scheduler di altro tipo.
Note introduttive
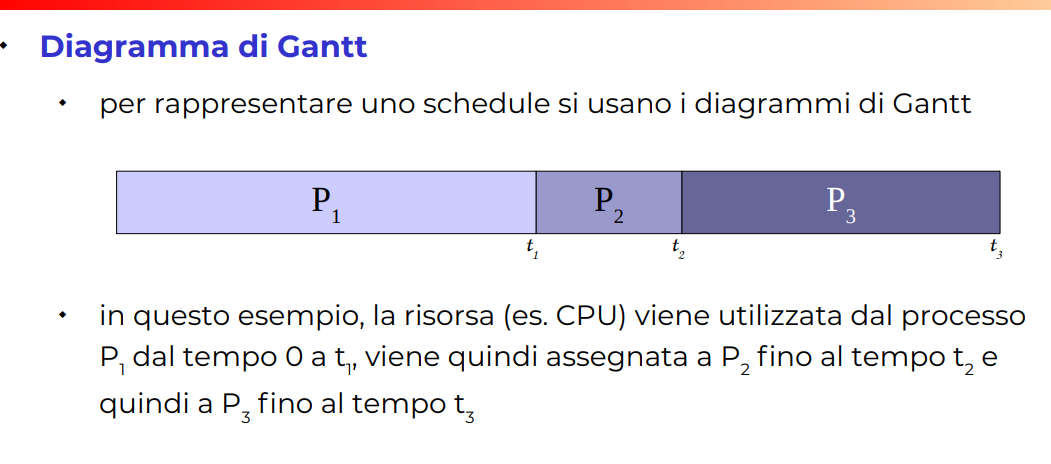
Diagramma di Gantt
Questo è il diagramma per presentare lo scheduling, ossia da quando a quando è eseguito cosa
-
Esempio gantt

Mode switch (link)
il mode switch è il passaggio fra user e kernel e viceversa, di cui abbiamo parlato in Note sull’architettura. si continua con lo stesso processo con permessi maggiori.
Context switch (4)
Context switch invece si passa da un processo all’altro, e bisogna salvare lo stato del vecchio processo nel PCB, come descritto in Processi e thread.
-
Esempio context switch
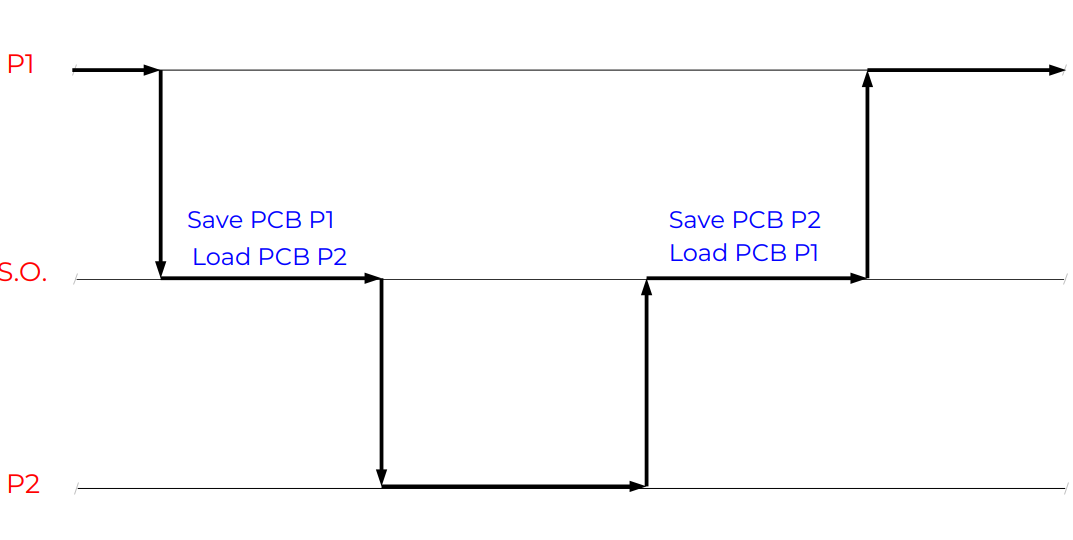
Serve un mode switch, fanno cose, un altro mode switch, e stessa sequenza per tornare indietro, sono 2 context swithc qui
Cause del context switch
-
Slide descrizione delle cause

Nota che per certe cause è necessario fare un context switch in altri casi no.
Vita di un processo
Si parla di tutti i passaggi fra int
-
Sistema attesa e interrupt
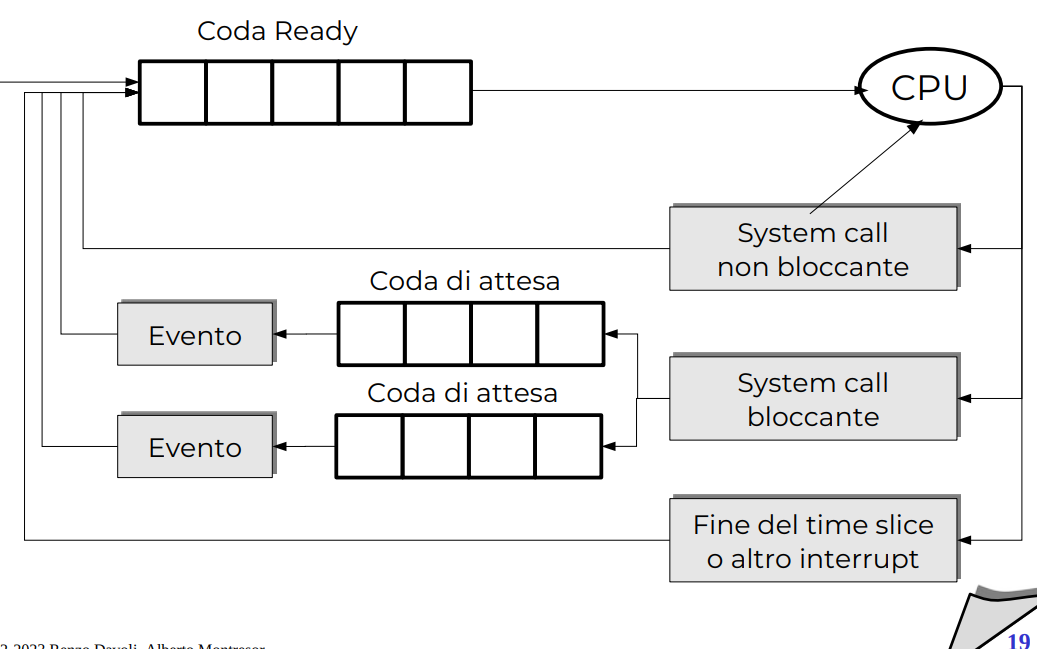
Praticamente il processo continua a runnare finché non lo fermano, con una syscall, con un interrupt di time slice oppure quando fa una syscall bloccante.
Quando è pronto a riprendere viene rimessa nella coda ready, e questa sarà la coda gestita dallo scheduler.
Catalogazione scheduler
Preemptive e non-preemptive
-
Slide descrizione preempty non preemptive


Non-preemptive è quando cambio processo solamente se cedo io, processo, il controllo.
Mentre preemptive è quando posso cambiare in ogni singolo caso.
- Vantaggi dello scheduling cooperativo
- non richiede alcuni meccanismi hardware come ad esempio timer programmabili
- Potevi monopolizzare la CPU se programmavi male.
- Vantaggi dello scheduling preemptive
- permette di utilizzare al meglio le risorse per questo motivo gli scheduler sono sempre preemptive ora.
Le risorse considerate (2)
Vogliamo ora trovare un modo per decidere in che modo decidere quale processo far partire e quale no.
-
Slide scelta dello scheduler

Sistemi batch
- Utilizzo della risorsa CPU, vorremmo che la CPU stia sempre a lavorare.
- Massimizzare il numero di processi completati, ossia massimizzare il throughput, se ci mette poco lo faccio.
- Turnaround time, ossia minimizzare il tempo di risposta, da quando il processo è sottomesso (issued) a quando è completato
Sistemi interattivi
- Tempo di attesa deve essere minimizzato (il tempo di attesa nella ready queue)
- Tempo di risposta deve essere minimizzato (vorrei avere feedback molto veloce), almeno non percepibile dall’umano.
When a request that is perceived as complex takes a long time, users accept that, but when a request that is perceived as simple takes a long time, users get irritated.
Sistemi real-time
-
Il fatto che un processo venga runnato prima di un certo tempo (altrimenti si perdono un pò di dati)
-
Libro sui metodi di valutazione dello scheduler

È importante questa parte perché sulle slides vengono valutati solamente turnaround e throughput!
NOTA: il tempo di utilizzo della CPU è lì riportata ma non è una buona misura!
Algoritmi di scheduling (!!)
FIFO: First come first served
Questo è l’algoritmo più banale, cioè appena arriva un processo. È una cosa molto semplice da implementare.
Solitamente non è molto veloce, buono per microcontrollori o comunque ambienti molto semplici. Per esempio se ho qualcosa che è CPU bound ritarda un sacco tutti quei processi IO bound
-
Esempio di processo lento

-
Altro esempio con convoy effect
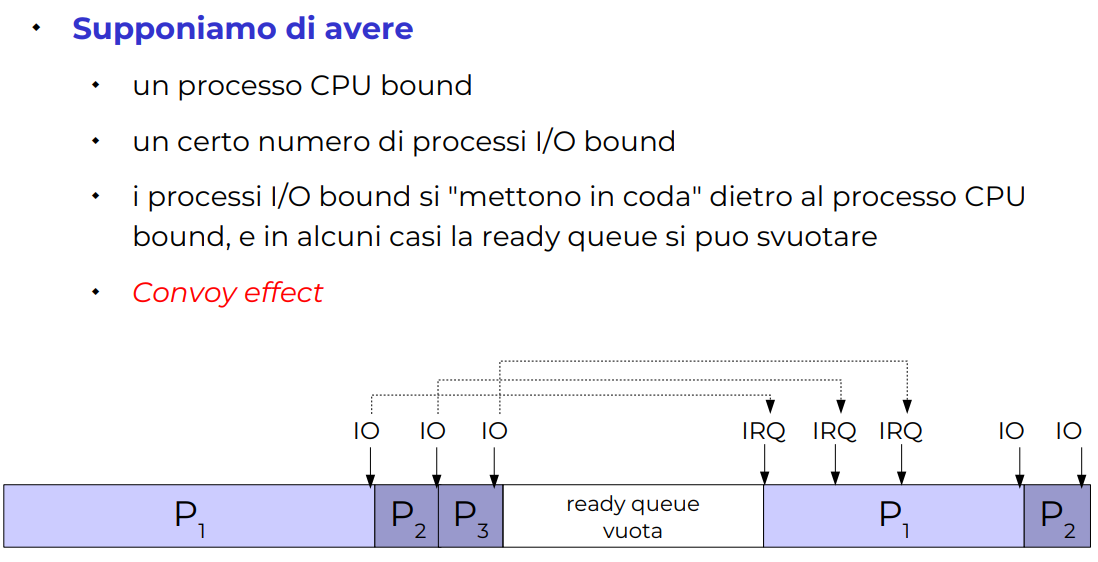
Quando ho il convoy effect, ho continuamente il process dispendioso che fa ritardare tutti, e ci sono intere zone vuote.
Processi CPU bound piccoli vanno dopo CPU bound larghi, è una cosa probabilistica, questo motiva la scelta di fare i lavori corti prima.
Shortest Job first
-
Slide shortest Job first

Si può notare che il tempo di turnaround e il tempo di attesa scendono di molto! ma come sapere quanto tempo ci metteranno ad eseguire? Non si può sapere a priori.
Si può anche dimostrare che è la miglior soluzione possibile, però non è possibile capire il cpu burst, posso solamente fare delle approssimazioni, che non sono per forza vere, non è possibile implementarle
MEDIA ESPONENZIALE
Questo è la media che si utilizza per approssimare, è la stessa media per le previsioni meteorologiche, che tengono conto del tempo.
-
Slide media esponenziale


VERSIONE PREEMPTIVE
Praticamente è un shortest remaining time first, che a seconda della predizione, si mette ad eseguire quello col tempo rimanente più piccolo. (nota potrebbe essere negativa la previsione).
Per la versioen non-preemptive si lascia
Round robin
-
Slide round robin

Questa è una soluzione pensata per sistemi interattivi, e a seconda del numero di questi processi, è possibile definire il quanto di tempo, ossia il massima durata in cui può rimanere in esecuzione, poi deve essere switchata.
Deve essere abbastanza corto che il tempo non sia percepibile umanamente, in questo senso sono interattivi.
Quando è in coda si mette in FIFO.
Non conviene mettere il quanto di tempo troppo piccolo perché si perderebbe troppo per switchare
IMPLEMENTAZIONE
C’è bisogno di un timer che genera interrupt ogni tot tempo, questo è il quanto di tempo per il round robin. Questa è proprio una cosa necessaria. per implementarlo.
Questo interrupt è settato! Nel senso ogni tot tempo da quando lo ho fatto partire.
-
Esempio

Scheduling a priorità
In questa parte i concetti importanti sono:
- Differenza priorità statica e dinamica
- I metodi per assegnare la priorità
- Aging (si implementa in un modo simile ai bit history visti in Paginazione e segmentazione
- Il sistema classi di priorità
È necessario un concetto di priorità, ad esempio se faccio video, non vorrei che sia rallentato da un servizio di posta, il primo ha bisogno di maggiore interattività, quindi avrei bisogno questo concetto di priorità.
La priorità può essere statica (che potrebbe fare starvation) o dinamica, per la dinamica si utilizza la tecnica di aging, in cui un processo ha una priorità naturale, che continua ad essere aumentato man mano resta nella coda di priorità.
statica si better for sistemi realtime per raggiungere.
Possiamo anche fare classi di priorità diverse e scelta la classe si può utilizzare la politica .
Questa politica è molto simile a quello utilizzato nei router in Data Plane.
- Server
- Interattivi
- Processi utente FIFO
- demoni e vuoti FIFO banali
-
Slide priorità (TODO: approfondire)

Esempio: https://www.geeksforgeeks.org/multilevel-queue-mlq-cpu-scheduling/
SISTEMI A REALTIME (non fare)
Ci sono certe cose aperiodiche e periodiche. Periodico come reattori nucleari che devono stare a guardare sempre qualcosa (come cose per i reattori nucleari).
Per periodici come rate monotonic (praticamente a priorità, quelli a frequenza alta sono di alta priorità) o earliest deadline first.
-
Spiegazione di chatGPT
Rate Monotonic Scheduling (RMS):
Rate Monotonic Scheduling is a widely used real-time scheduling algorithm. The RMS algorithm is based on priority assignment to periodic tasks, where the task with the shortest period has the highest priority. The scheduling of tasks is done in a way that the higher-priority task always preempt the lower-priority task.
The RMS algorithm assumes that the execution time of all tasks is known in advance and that there are no other sources of delay, such as I/O or interrupts. This is known as the “static scheduling” assumption.
Earliest Deadline First Scheduling (EDF):
Earliest Deadline First (EDF) is another real-time scheduling algorithm. In EDF, each task has a deadline, and the task with the earliest deadline is scheduled first. The deadlines can be either hard (absolute) or soft (flexible). Hard deadlines must be met, while soft deadlines can be missed, but a penalty is incurred for each missed deadline.
Like RMS, EDF is based on the assumption of static scheduling, which means that the execution time of tasks is known in advance and there are no other sources of delay. EDF can also handle aperiodic tasks, which do not have a fixed period but must be executed within a specified time limit.
The key difference between RMS and EDF is that RMS uses a fixed priority assignment based on task period, while EDF assigns priority dynamically based on the task deadline.
In summary, both RMS and EDF are real-time scheduling algorithms used to schedule tasks in real-time systems. RMS assigns priority based on the task period, while EDF assigns priority dynamically based on the task deadline.