Next time, use this resource.
Di solito è utilizzata per ridurre lo spazio utilizzato trattenendo la maggiore quantità di informazione possibile, utilizzata spesso in Principal Component Analys
-
Enunciato SVD slide
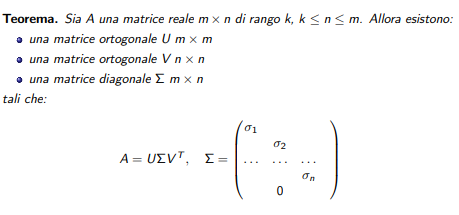
-
Immagine esplicativa
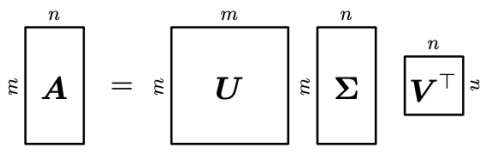
Questo è qualcosa che si può applicare a qualunque matrice. Sono di particolare interesse le matrici con numero di colonne maggiore del numero di righe.1
-
Slide vecchia

Relazione valori singolari con AAt
Con k ho il numero di numeri non zero che sono il rango della matrice. Questa matrice è particolare, la chiamiamo gramiano ed è sempre definita positiva.
-
Slide

Quindi i valori singolari che sono gli autovalori della matrice sono
- se k è il rango di , ho k elementi diversi da 0.
Il motivo per cui succede quanto sopra è perché è come se stessi facendo il cambio di base per trovare una matrice diagonale! Cambio di Base, e non c'è nessuna relazione altra fra la matrice di A e il valore singolare, deve essere con AAt!
-
Relazione molto importante (!!!!!)
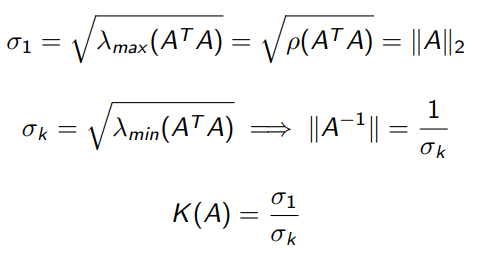
Vettori singolari sinistri e destri
Definiamo in questo modo i vettori associati a che formano una base ortonormale rispettivamente di . E in particolare sono le colonne delle matrici
NOTA: è molto probabile che la relazione sotto che lega vettori singolari sinistri e destri sia errata perché sulla pagina di wiki u e v sono invertite. È più importante il fatto che i vettori singolari sinistri e destri sono rispettivamente autovettori di AAt e AtA.
-
Slide

Decomposizione diadica
![[image/universita/ex-notion/Minimi quadrati/Untitled 11.png]]
In pratica con la decomposizione a valori singolari, e utilizzando i vettori singolari si può dimostrare che
Espandere questi calcoli è abbastanza easy creddo, perché la matrice di mezzo è molto semplice da gestire. L’intuito per sta parte (che è l’unica cosa di cui si è preoccupata di spiegare) è che è utile qui il concetto di un prodotto esterno che po
Risoluzione minimi quadrati con SVD
![[image/universita/ex-notion/Minimi quadrati/Untitled 12.png]]
-
Dimostrazione


Regressione Polinomiale (!)
Abbiamo un insieme di dati, vogliamo creare un algoritmo che stimi la funzione migliore per approssimare i dati.
Siano dati un insieme di punti , sia un polinomio p così definito
, vogliamo andare a definire per bene i valori dei coefficienti in modo che aderiscano ai dati.
Per fare questo, in pratica è la risoluzione di certi errori.
In pratica mi costruisco la matrice di vandermonde per tutti gli input di dati, di n numero di colonne, con n l’esponente massimo del polinomio che voglio andare ad approssimare.
Poi faccio cose per minimizzare l’errori di questo e lo possono fare con SVD o minimi quadrati (nel cosi in cui il rango fosse giusto).
Importante per questa parte la matrice di vandermonde.
Pseudo inversa (4)
-
Slide

Questa definizione ci permette di scrivere il problema dei minimi quadrati in modo più clean, infatti la soluzione della SVD diventa
, come se stessi prendendo l’inversa 😀, quindi ci permette di semplificare questa notazione.
Si può notare che l’inversa possiede tutte le proprietà della pseudoinversa.
In soldoni: inverto le matrici di vettori singolari e inverto tutti i valori singolari (prendo iil loro reciproco).
Importanti sono alcune loro proprietà (hermitiana per AA* e A*A, ossia simmetrica, inversa debole e l’altra boh).
Secondo la definizione di moore-penrose quelle 4 proprietà sono sufficienti per una pseudoinversa, in questo caso abbiamo la pseudoinversa della SVD, che è una cosa leggermente diversa (cioè istanziazione specifica della pseudoinversa).
Condizionamento in LSQ (non fare)
Questa sezione ha cose da ricordare a memoria (già leggermente presentate in precedenza) quindi non ha molto senso dare attenzione a sta roba brutta, imparare poi a memoria il costo dei vari argoritmi bruuh
Vogliamo in questa sezione andare ad indagare quanto influenza il numero di condizione tutte le tecniche che abbiamo introdotto in questo capitolo.
![[image/universita/ex-notion/Minimi quadrati/Untitled 16.png]]
![[image/universita/ex-notion/Minimi quadrati/Untitled 17.png]]
Da ricordarsi di Norme e Condizionamento, che il condizionamento ci dice quanto cambia la soluzione quando cambio i dati (la b)