This note is still a TODO.
Transliteration is learning learning a function to map strings in one character set to strings in another character set. The basic example is in multilingual applications, where it is needed to have the same string written in different languages.
The goal is to develop a probabilistic model that can map strings from input vocabulary $\Sigma$ to an output vocabulary $\Omega$.
We will extend the concepts presented in Automi e Regexp for Finite state automata to a weighted version. You will also need knowledge from Descrizione linguaggio for definitions of alphabets and strings, Kleene Star operations.
Weighted finite-state automata
Definition of WFSA
We take the 5-tuple of the finite-state automata and add two functions $\lambda : Q \to \mathbb{K}$ and $\rho: Q \to \mathbb{K}$ (which represent the initial and final weighting function) and the transition function to a multiset (somewhat similar to non deterministic finite state automatas) $\delta : Q \times (\Sigma \cup \varepsilon)\times \mathbb{K} \times Q$, which tells us some sort of probability of transition.
Intuitively $\lambda$ and $\rho$ tells us how much is that starting or finishing sequence probable. Then a path in the WFSA has a natural notion of probability. If it satisfies other axioms, see Language Models then it can be effectively also used as a language model.
We then need to go to define the notions of paths, yield, length of a path, if it is ambiguous or unambiguous in order to be able to speak about these automatas.
 Ambiguous if there is at most one accepting path for $s$.
Ambiguous if there is at most one accepting path for $s$.
The interesting thing about WFSA is that they can model many models! Part of Speech Tagging’s conditional random fields are WFSA, Language Models’s N-gram models are WFSA, also HMMs are WFSAs! So this model is quite general! The nice thing is that if you develop an algorithm for WFSAs then you can use the same algo for the other models too.
N-grams to WFSA
This representation of N-grams can be easily interpreted as WFSA. The difficult thing is to define the space of the states. There is a small technical thing to include all the BOS and EOS.

Relations to CRF
$$ p(y|x) = \frac{1}{Z(x)} \exp\left(\sum_{i=1}^n \sum_{j=1}^m \lambda_j f_j(\langle y_{i-1}, y_i \rangle, x)\right) $$Assuming additive decomposability.
CRFs are WFSAs

With CRFs we only had 1-1 alighments, WFSA allow to have one to many or many to one in different formats, so it is more general.
Disadvantages for transliteration
CRFs can have only a single emission per input token. This is a problem for transliteration where we can have many outputs for a single input. WFSA can model this.
We can observe that CRFs model emissions as $a : b$ where $\lvert a \rvert = \lvert b \rvert = 1$ each of them has length 1. This also corresponds to cases where we have a strict alignment between the input and output alphabet.
Pathsum
Def: path and inner path weight
$$ \text{weight}(\pi) = \bigotimes_{i = 1} ^{n} w_{i} $$$$ \text{weight}(\pi) = \lambda(q_{1}) \otimes \left( \bigotimes_{i = 1} ^{n} w_{i} \right) \otimes \rho(q_{n}) $$We accept the state if the path weight is $\neq 0$. TODO.
Transducers
Definition of Transducers
Same thing as WFSA, but we also add an output alphabet. We observe that this definition naturally translates the input text to an output format. The nice thing is that it builds upon that formal languages machinery.

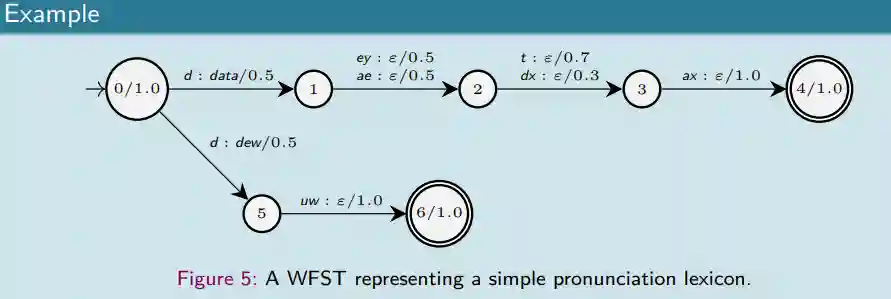
Composability
$$ T := T_{1} \circ T_{2} \mid T(x, y) = \bigoplus_{z \in \Omega^{*}} T_{1}(x, z) \otimes T_{2}(z, y) $$Intuitively, we say that the probability that the composed transducer $T$ goes from $x$ to $y$ is the sum of the probabilities of all the possible intermediate states $z$. This is the same idea as marginalizing over another variable in probability, here we are somewhat marginalizing over another alphabet.
Naive Explicit construction
TODO: You should provide the algorithm for exclicitly building the transducer.
Accessible construction
The main idea is to build states that can be accessed. TODO: explain and present this algorithm.
Translitteration
General strategy is have WFST for a language, another for the other, then compose them so that we have a transducer.
Alignment
TODO:
Collapsing into single Matrix
TODO: this is content of slide 97. You need to understand the details well, better if you can work out the math.
Lehmann’s Algorithm
Lehmann’s algorithm Lehmann, 1977 is a very general dynamic program for computing the Kleene closure of matrices over arbitrary closed semirings.
 We use this algorithm to compute normalizer (or other things) for the
It's very easy to see that Floyd Warshall's all shortest path (see Grafi#Algoritmo di Floyd-Warshall) is just Lehmann's algorithm on a tropical semiring, with Kleene start $=0$.P
We use this algorithm to compute normalizer (or other things) for the
It's very easy to see that Floyd Warshall's all shortest path (see Grafi#Algoritmo di Floyd-Warshall) is just Lehmann's algorithm on a tropical semiring, with Kleene start $=0$.P
Connection with Gauss-Jordan
TODO
Backward algorithm for Graphs
TODO: present and prove how this works, and that this is correct. This should be easy, but I never really seen a proof of correctness over topologically sorted nodes :) need to figure that out.