What is a part of Speech?
A part of speech (POS) is a category of words that display similar syntactic behavior, i.e., they play similar roles within the grammatical structure of sentences. It has been known since the Latin era that some categories of words behave similarly (verbs for declination for example).
The intuitive take is that knowing a specific part of speech can help understand the meaning of the sentence.
Definition of the problem
We assume there are some given categories (it has some drawbacks, because we can define too many categories sometimes, making the thing more difficult), for example, in a classical analysis, we would have articles, noun verbs.
It is possible to see this problem as a path in a graph, even though currently I don’t know what is the exact advantage for this. These kind of graphs are called trellis.
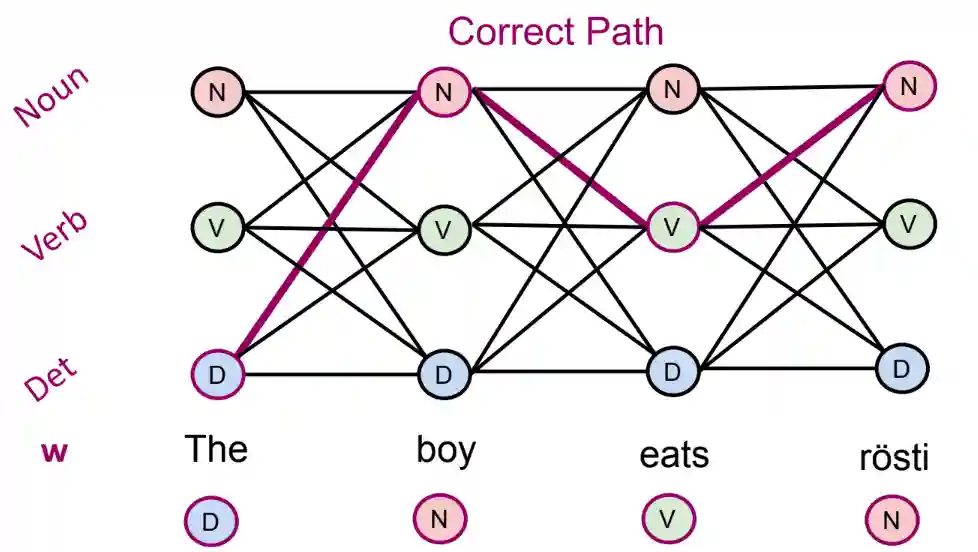
There is a relation between statistica models and combinatorial algorithms. We should use this relation to score the path.
Conditional Random Fields
These are just Log Linear Models on structured data (e.g. lattices), they were first introduced in 2001, and first they were not seen as log linear models. It’s very similar to Hidden Markov Models, which are similar to the Kalman Filters from some kind of view.
We define our conditional probabilistic model for sequence labeling, aka conditional random field:
$$ p(t \mid w) = \frac{\exp(s(t, w))}{\sum_{t' \in \mathcal{T}^{N}} \exp(s(t', w))} $$where $s$ is the scoring function that marks the compatibility of a tag for a sentence. The score could also be negative. If the score is linear the whole random field would be a in The Exponential Family. The only requirement is that it returns a scalar.
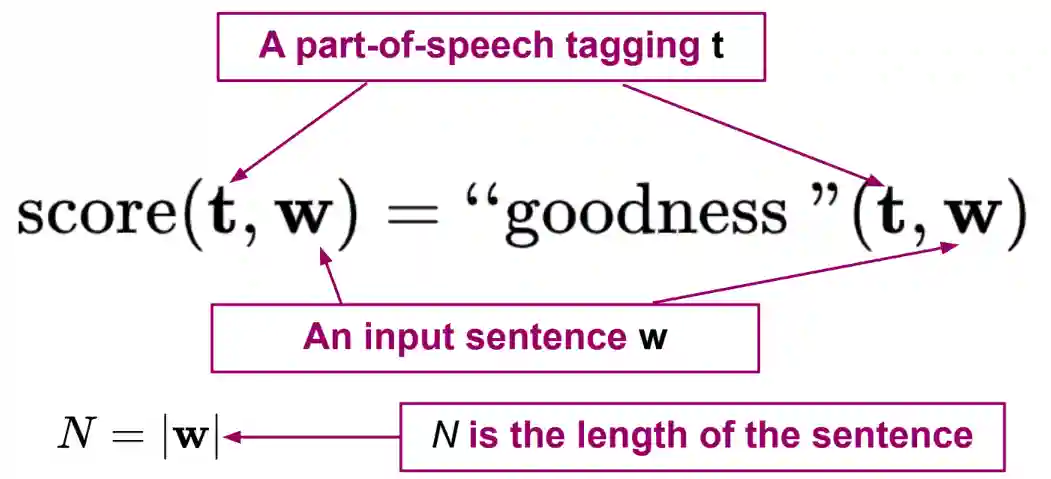
So higher score is better, lower score is worse. But this algorithm is very slow! Computing the normalizer takes $\mathcal{O}(\lvert \mathcal{T} \rvert^{N})$ time. Assuming more structure (it is free information from another point of view), allows to have faster algorithms.
Additively decomposable assumption
We assume additively decomposability into the score function in order to bring down the complexity of computing the normalizer for the exponential space, which actually makes the problem tractable. Now we assume the score function to be: $$ s(\boldsymbol{t}, w) = \sum_{n = 1}^{N} s(\langle t_{n - 1}, t_{n} \rangle , w) \implies \exp(s(\boldsymbol{t}, w)) = \exp\left( \sum_{n = 1}^{N} s(\langle t_{n - 1}, t_{n} \rangle , w) \right)
\prod_{n = 1}^{N} \exp(s(\langle t_{n - 1}, t_{n} \rangle ,w)) $$ which means: instead of looking at the whole structure we only look adjacent tags. This is a strong assumption, but it’s ok to start doing something that might be useful. NOTE: we use a special symbol when $n = 1$. This makes it easy to compute the score, because we can just take adjacent couples instead of the whole string.
If the score is a neural network, then we can train this function without exactly knowing how they are made!
This has a clear visual interpretation by putting a score on a Arc, now we have weighted directed acyclic graph. But then we can use Backpropagation algorithms too!
Emission and transition
$$ s(\langle t_{n - 1}, t_{n} \rangle, w) = s_{\text{emission}}(t_{n}, w_{n}) + s_{\text{transition}}(t_{n - 1}, t_{n}) $$Simplifying the partition function
After we have a score, then it is just a shortest path problem, a combinatorial optimization problem, it’s nice to see the derivation of why it’s easy to compute the normalizer:
$$
\begin{align} \sum_{t \in \mathcal{T}^{N}} \exp \left{ \sum_{n = 1}^{N} s(\langle t_{n - 1}, t_{n} \rangle , w) \right} =\ =\sum {t{1:N} \in \mathcal{T}^{N}} \prod_{n = 1}^{N} \exp \left{ s(\langle t_{n - 1}, t_{n} \rangle , w) \right}\ = \sum {t{1:N-1} \in \mathcal{T}^{N-1}} \sum_{t_{N} \in \mathcal{T}} \prod_{n = 1}^{N} \exp \left{ s(\langle t_{n - 1}, t_{n} \rangle , w) \right} \ = \sum {t{1:N-1} \in \mathcal{T}^{N-1}} \prod_{n - 1}^{N - 1} \exp \left{ s(\langle t_{n- 1}, t_{n} \rangle , w) \right} \times \sum_{t_{N} \in \mathcal{T}} \exp \left{ s(\langle t_{N - 1}, t_{N} \rangle , w) \right} \ = \sum_{t_{1} \in \mathcal{T}} \exp \left{ s(\langle t_{0}, t_{1} \rangle , w) \right} \times \left( \dots \times \sum_{t_{N} \in \mathcal{T}} \exp \left{ s(\langle t_{N - 1}, t_{N} \rangle , w) \right} \right) \end{align} $$
Where we have just applied a distributive property in the 4 line, and reapplied the same line of reasoning over and over again. This is somewhat similar to factorizing polynomials. Now we have a simple and fast way to calculate it, it’s just a linear number of terms. The deep insight is that here we derived an algorithm by just doing some algebra! Is there some deep links between an algebraic view of computation and algorithms with algebra?
The backward algorithm
We see now all the algorithm for the backward dynamic programming solution to compute the normalizer (remember the visual interpretation that we have).

The Viterbi algorithm
How to find the highest-scoring tagging for a certain input sequence $w$? We just add a max operator instead of the sum! This makes it quite easy. Viterbi was a code cracker times ago.
This is very similar to the backward algorithm used to calculate the partition function:

The only thing we need is a semi-ring.
Relation with Logistic Regression
CRF can be seen as a generalization of Logistic Regression for sequences prediction. See Linear Regression methods for something about regression methods. TODO: say why this is true.
Relation with HNN
CRF are also a more flexible generalization of HNN models. TODO: say why this is true.
Semirings
This section has been moved to Semirings.