How can we coordinate services to actually understand what they are doing, or what the user wants them to do? How to manage networks errors? This note will mainly focus on high level communication protocols to coordinate this kind of communication.
Remote Procedure Calls
History: the Stub
This has been the main idea, introduced in 1984, using the idea of stubs, see (Birrell & Nelson 1984). The system basically calls the remote procedure as if it was local on the high level, but on a lower level a network request is sent. The architecture has remained the same in these years. It hides all the complexity in the stub (marshaling, binding and sending, without caring about the sockets and communication matters). One problem is that it might be hiding the complexity too well. The programmer has surely an ease of programming, but design consideration should consider overloads generated by the network communication.
Implementation of the RPC
- How to determine location and identity of the Callee?
- How to implement semantics for address argument, if there is no shared addressing space?
- How to handle failures of network communication?
These problems are solved with the following key features:
- Stubs: basically generated interfaces that describe the kind of data that is transferred or received. This enables linkage between the two procedures.
- We need a IDL (interface definition language): to define the language-agnostic interface.
- Serialization/Marshaling: the data is transmitted in a format good for transmission, but we would need to unpack and move it again to a processable format.
- Binding: knowing IP address and port, having some discovery service that tells you where the remote server is, this is called the name and directory service (big problem).
The implementation still uses a format introduced in the 90'

Distributed Computing Environment, a RPC framework from the 90'
RPC is Client-Server
RPC is quite a low level construct to build these systems. Easy to use, hiding complexity from the programmer, yet it was build with the classical client-server architecture in mind, which sometimes might be outdated in modern communication frameworks. Nice thing about the RPC structure is that it is fast. Serialization is often costly, costs about 6% of the cycles of a server (see (Kanev et al. 2015)).
Design Considerations
Transparency of server and call
This section is from a design perspective: would a developer be better off if calling local procedures and remote procedures uses the exact same code?
- YES -> meaning it is easier to implement, easier to manage the code
- Today we know that hiding this is a bad idea. I have also personal experience for this thing. Ask me about it offline.
- NO -> meaning that the developer should be aware of the fact that it is a remote procedure call, and should be aware of the network communication and the possible errors that can happen, which could directly affect the performance and structure of the code.
Should the position of the remote server be transparent?
- YES -> the system should be able to move the server around easily, and the client should not care about it, good for fault tolerance too.
- NO -> the client should be aware of the fact that the server is remote. This should make the design easier, with less overhead of the configs.
Failure Semantics in RPC
- High latency: you need to wait for the other to answer
- Tight coupling: the two systems need each other to function.
We have partly analyzed this concept in Message Passing.
You should also define some failure semantics, this is usually implemented by attaching ids to the messages.
- At least once: the client makes the call again until it succeeds and receives a response. This is usually implemented in the client side.
- At most once: the server remembers the calls, and executes the call only once, even if it is called multiple times. This is usually implemented on the server side.
- Exactly once: Mix of the previous two: it needs both the client and the server.
Real Frameworks
CORBA

Image from CCA ETHz 2025 course slides
gRPC
Now gRPC is built on top of HTTP most of the times, easier to handle discovery and reliability of the communication.
- Often used for performance critical systems, in the cloud.
- More scalable compared to classical RPC
- More efficient compared to REST. Over time, implementations of RPC have evolved to adopt ideas from REST (see #REST) such as gRPC (open source, initially from Google)
- gRPC uses a standardized representation for serialization (Protocol Buffers, also from Google). Several such representations have been created by cloud providers, e.g:
- Ion (Amazon)
- Apache Thrift (Facebook/Meta)
- Microsoft Bond
- Operates on top of HTTP/2 instead of TCP/IP
REST
See HTTP e REST. The thing to remember is that
- Rest is more scalable and interoperable compared to RPC.
- Might suffer from long chain of calls, good design patterns help in this context.
Design Patterns for the Cloud
This is a different form of design patterns compared to Design patterns for software engineering, nonetheless important.
REST becomes problematic when used in large-scale multi-tier settings as interaction becomes cumbersome and requires too many steps in environments where network latency matters (REST was based on the web and HTTP, not for a data center)
A chain of too many calls would make the service quite slow.
Materialized view
Since most services just retrieve data, it might be helpful to put a cache in the middle to speed up the communication (so that I don't need to send a request). Often this is done in the form of a materialized view of the needed information. This is a classical design pattern, we also talked about it briefly when we studied Relational Algebra and also in Apache Spark when caching intermediate results.
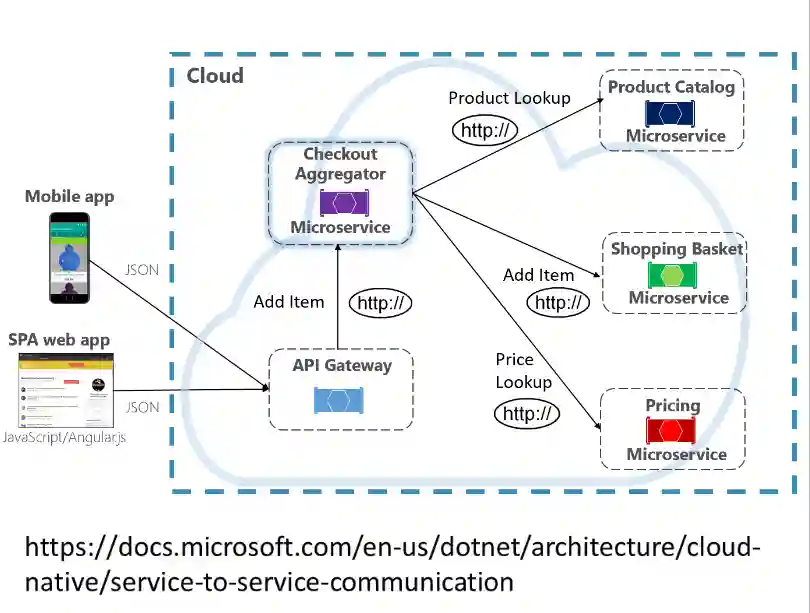
Service Aggregator
The idea is that instead of a complex sequence of calls, implement a single centralized service whose role is just to make calls. So that there are no complex dependencies anymore, only one with the service aggregator.
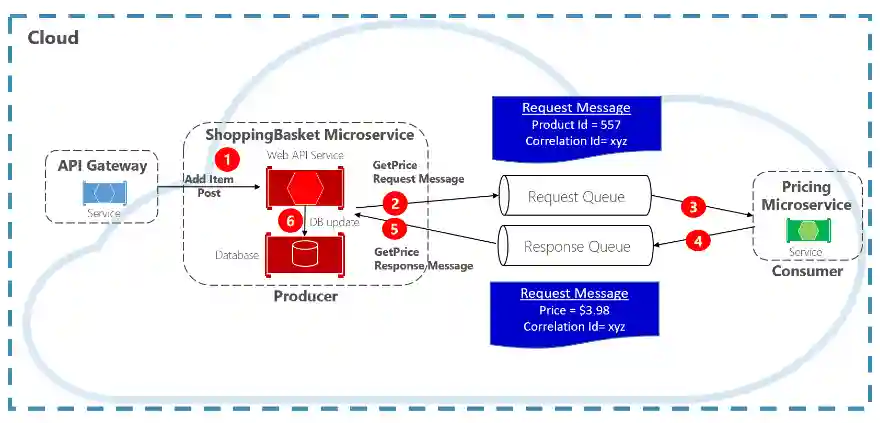
Message Queues
We can decouple the services using queues. When the provided requests does not match the consuming rate, this is a good pattern.
The drawback is that we are adding some latency, the benefit is that we are decoupling the services, which brings an easier development. It also allows for a transactional manner of storing requests, so that these can be persisted and audited.
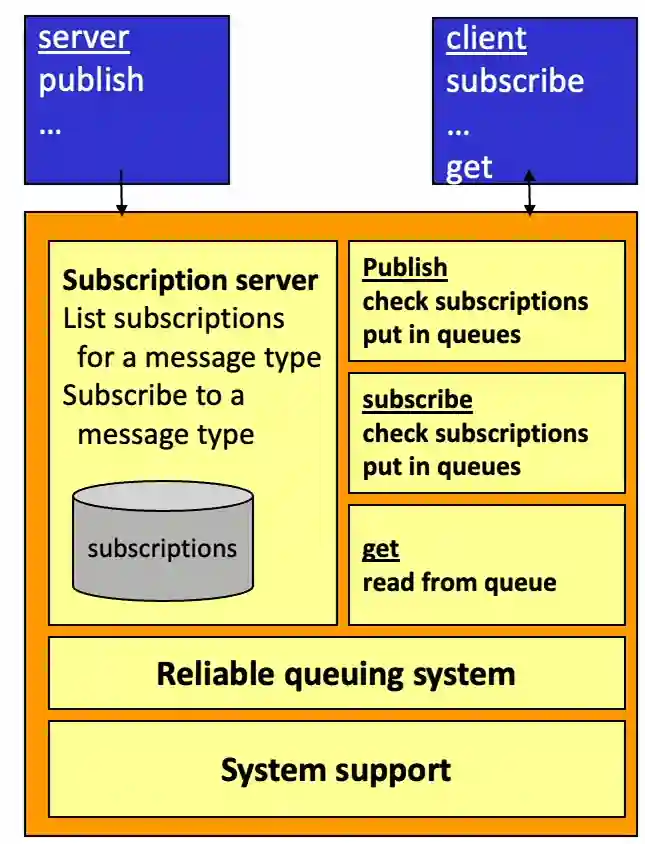
Message Queuing Services
Basic Properties
Ordering or messages and charging can be defined by the user. Also dropping queues etc.
Basic Functions of Queues
A message queuing system typically
- Provides queues for clients to PUT and GET messages
- Stores the messages persistently to guarantee they survive failures
- Makes the insertion and deletion of messages transactional
- Monitors queues and accesses for access control, scalability, routing, etc.
- Manages the creation, deletion, and access to messages and queues
Persistence of messages
A good thing is that now queues can be persisted in the queuing system. Receivers can read when service is up. Services can multiplex requests to this system. This is a great thing with regards to the disassociated scaling of the resources.
Implementation of Queuing systems
Database implementation
We can implement it using a database, so messages are simply entries in this database. We have transactions on this database. The important thing to remember is that messages are persistent and consumed in this manner. Separate domain with respect to producer and consumer of these messages.
Azure Store Queues
It is just building these queues on top of cloud buckets (see Cloud Storage). This service provides
- No ordering
- Elimination after 7 days of the message
- Only pay for storage space.
- Large capacity, and HTTP interfaces.
- HTTP access.
- Limited persistence.
Amazon SQS
With this system we have two possible queues:
- Best effort ordering You have at least once semantics.
- FIFO queues with extraction (different pricings), here is exactly once semantics.
- Charged per million requests (standard queues are cheaper than fifo) and GB of readout data.
- Elastic deployment, with multiple copies across availability zones.
- No volume limitation.
Azure Service Bus Queues
Based on a message broker, it provides the typical features of a message queuing system:
- FIFO delivery
- Transactional access
- Duplicate detection
- Supports queue partitioning across several message brokers (for scalability)
- Session IDs used to correlate messages that belong together (correlation IDs)
- Size of the queue is limited.
- Charged on a base cost and per operation costs.
Publish and Subscribe
Azure Event Grid
This is an example of a publish-subscribe based service, but more general: event based systems is an architectural approach to distributed computing, while publish and subscribe is an implementation. Guarantees:
- Event delivery is in 24 hours with retries.
- Notifications that can be sent to many destinations.
- This is event based, so a little different compared to queues.
References
[1] Birrell & Nelson “Implementing Remote Procedure Calls” ACM Transactions on Computer Systems Vol. 2(1), pp. 39–59 1984
[2] Kanev et al. “Profiling a Warehouse-Scale Computer” ACM 2015