A data model is an abstract view over the data that hides the way it is stored physically.
The same idea from (Codd 1970) This is why we should not modify data directly, but pass though some abstraction that maintain the properties of that specific data model.
Data Models
Tree view
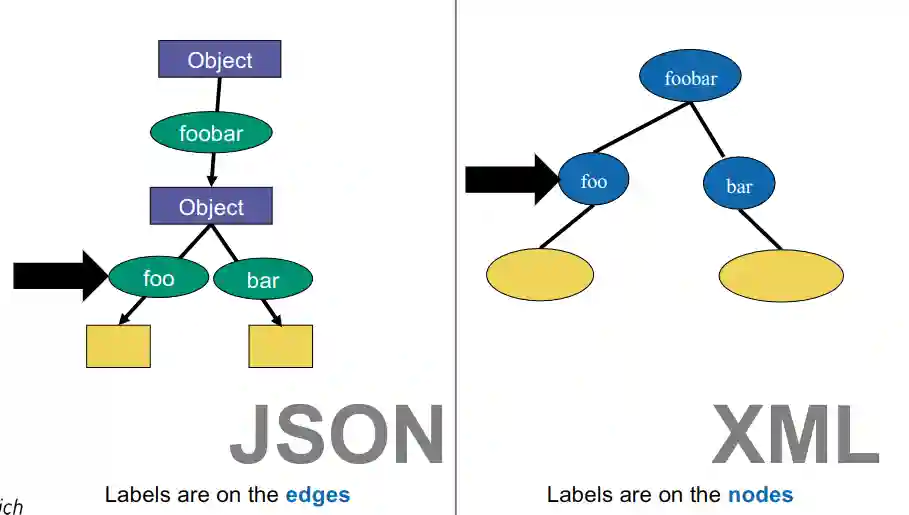
We can view all JSON and XML data, as presented in Markup, as trees. This structure is usually quite evident, as it is inherent in their design. Converting from the tree structure to a memory model is known as serialization, while the reverse process is called parsing.
A key distinction lies in edge labeling for JSON models and node labeling for XML models. Additionally, XML accessors are bidirectional, meaning they include a parent pointer, whereas JSON lacks this feature.
XML Information Set
This is how actually is stored in memory when the XML file is parsed into memory. It’s also quite easy to implement after a standard programming course. There are many other parts of the information set, but we will not cover them in the current course (e.g. Namespaces, comments, are not covered.)
Document Information Item
The document information item is the root node of the three view; the first element of XML file should be always present even if the doctype declaration is not present, this is the children of this information item.
Element Information Item
This is just the element tag, as it is explained briefly in Markup. Parents could be the root document item, or other information items. It can have attributes, children and the local name (the name of the tag).
Attribute Information Item
Here we have a key (called local name), the value, and the parent, which is the element that owns this attribute.
Text Information Item
We just have the text value and the owner for this element.
Validation
Even with a well-formed JSON or XML document, the structure can still be quite disorganized. Imagine a document where values are scattered haphazardly. Our goal should be to impose some order on these documents by providing them with an abstract model of the data. We say that a JSON or XML document adheres to a model when it is correctly validated against that model. In this section, we will explore specific validation modes available for JSON and XML. Usually this validation step is done after the file has been correctly parsed into the memory.
There are some advantages in validation, one is the processing speed. With normalized data, we can use some specific data structures tailored to process that format, and store it more efficiently.
Atomic Types
We need to remember that there are some default atomic types for the data model, which are different from the 4 atomic types present in the well-formedness of JSONs.
- Strings
- Numbers
- Booleans
- Null values
- Dates and times (you need to be careful about month - day division, number of days is dependent of year and months)
- Time intervals
- Binary
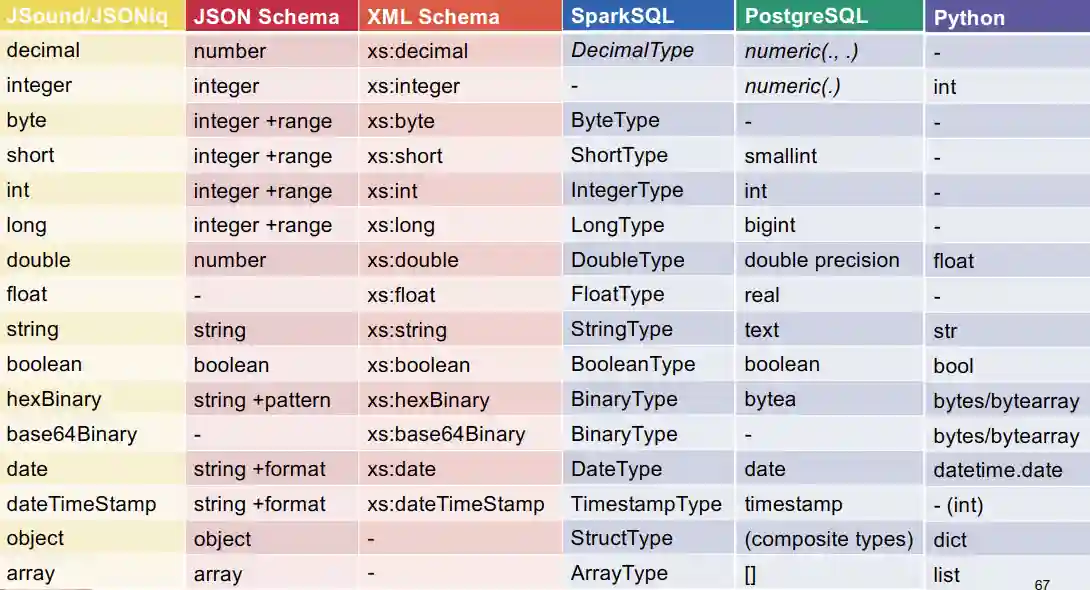
These atomic types are usually common everywhere, but the names could vary. The following is a table that summarizes the various names for different technologies
Lexical and Value space
All atomic types have in common that they have a logical value space and a lexical value space. The logical value space corresponds to the actual logical abstraction of the type (e.g., a mathematical set of integers), while the lexical value space corresponds to the representation of logical values in a textual format (such as the decimal, or binary, or hexadecimal representation of an integer).
So the Value Space is what it wants to represent, while the lexical space is what is actually stored. For example, an image could be stored using base64 encoding.
Static and Dynamic schemas
Dynamic schemas allow for more flexibility, while static schemas are more rigid. The former are more common in JSON, while XML schemas are just static.
For example dynamic schemas can allow for keys that are not defined in the schema if the additionalProperties is set to true.
JSON Validation
There are some specific types in JSON, and we need to know them well. One of the most famous validation frameworks with JSON is JSound (developed at ETH for teaching purposes), you should know the syntax very well for the scope of the course. See slides, for example here. Another checker could be JSON Schema, which is standardized by the W3C.
Structured Types
In this case, there are no additional types beyond the standard array and map values typically found in JSON. The only distinction is that we might need to impose a cardinality constraint.
Then there are many many ways to describe a requirement for the data model some common ways you need to keep in mind are
- Cardinality: How many times a specific element can appear.
- Requiring presence of a key
- Open and closed object types (difference between JSound and JSON schema).
- Primary key constraints, null and present values. (In jsound we have special characters ?, = and @)
- Any values
- Type unions and intersections, negation, exclusive.
Example of JSON Validation
Let’s say we want to build a schema for:
{
"name": "John Doe",
"age": 30,
"email": "john.doe@example.com",
"isEmployee": true,
"skills": ["JavaScript", "Python", "SQL"],
"address": {
"street": "123 Main St",
"city": "Zurich",
"postalCode": "8000"
},
"projects": [
{
"title": "E-commerce Website",
"durationMonths": 6
},
{
"title": "AI Chatbot",
"durationMonths": 4
}
]
}
Then a possible schema would be:
{
"$schema": "<a href="http://json-schema.org/draft-07/schema#",">http://json-schema.org/draft-07/schema#",</a>
"type": "object",
"properties": {
"name": {
"type": "string",
"minLength": 1,
"description": "The full name of the person."
},
"age": {
"type": "integer",
"minimum": 18,
"maximum": 65,
"description": "Age must be between 18 and 65."
},
"email": {
"type": "string",
"format": "email",
"description": "A valid email address."
},
"isEmployee": {
"type": "boolean",
"description": "Whether the person is an employee or not."
},
"skills": {
"type": "array",
"items": {
"type": "string"
},
"minItems": 1,
"uniqueItems": true,
"description": "A list of unique skills."
},
"address": {
"type": "object",
"properties": {
"street": {
"type": "string"
},
"city": {
"type": "string",
"enum": ["Zurich", "Geneva", "Basel"],
"description": "City must be one of Zurich, Geneva, or Basel."
},
"postalCode": {
"type": "string",
"pattern": "^[0-9]{4}$",
"description": "A 4-digit postal code."
}
},
"required": ["street", "city", "postalCode"],
"description": "Address details."
},
"projects": {
"type": "array",
"items": {
"type": "object",
"properties": {
"title": {
"type": "string"
},
"durationMonths": {
"type": "integer",
"minimum": 1,
"description": "Project duration must be at least 1 month."
}
},
"required": ["title", "durationMonths"],
"description": "Details of projects."
},
"minItems": 1,
"description": "A list of projects."
}
},
"required": ["name", "age", "email", "isEmployee", "skills", "address"],
"additionalProperties": false
}
XML Validation
XML Schema is one of the most famouse ways to validate XMLs. This is an example of a XML schema
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema xmlns:xs="<a href="http://www.w3.org/2001/XMLSchema">">http://www.w3.org/2001/XMLSchema"></a>
<xs:element name="foo" type="xs:string"/>
</xs:schema>
We see that they are inside a namespace, then we have special tags for elements, types and attributes.
We can also control the number of times an element appears in the document.
XML Types
Here are some types taken from the Book.
- Strings:
xs:string, xs:anyURI(for strings containing a URI); - Numbers:
xs:decimal, xs:integer, xs:float, xs:double, xs:long, xs:int, xs:short, xs:byte, xs:negativeInteger, xs:positiveInteger, xs:nonNegativeInteger, xs:nonPositiveInteger, xs:unsignedByte, xs:unsignedShort, xs:unsignedInt, xs:unsignedLong; - Dates and times:
xs:date, xs:time, xs:dateTime, xs:gYearMonth, xs:gYear, xs:gMonth, xs:gDay, xs:gMonthDay, xs:dateTimeStamp; - Time intervals:
xs:duration, xs:yearMonthDuration, xs:dayTimeDuration; - Binary types:
xs:hexBinary, xs:base64Binary - Booleans:
xs:boolean - Nulls: does not exist as a type in XML Schema (JSON specific).
Normally one can also define custom atomic types! In this case we use keywords like xs:simpleType and xs:restriction or xs:complexType for more complex types (nested elements or sequences).
Facets
An XML facet refers to a constraint or rule applied to XML data types, particularly in XML Schema (XSD), to define specific properties or restrictions for elements or attributes within an XML document. Facets are used to specify conditions such as length, value ranges, patterns, and other constraints on the data stored in an XML document.
Facets are often associated with simple types in XML Schema and help enforce validation rules for the values of elements or attributes. For example, you can use facets to ensure that an element contains a number within a specific range or a string that matches a particular pattern.
Example of XML validation
<Library>
<Book isbn="978-3-16-148410-0">
<Title>Effective Java</Title>
<Author>Joshua Bloch</Author>
<Year>2018</Year>
<Genre>Programming</Genre>
</Book>
<Book isbn="978-1-118-06333-2">
<Title>Clean Code</Title>
<Author>Robert C. Martin</Author>
<Year>2008</Year>
<Genre>Programming</Genre>
</Book>
<Member id="101">
<Name>John Doe</Name>
<Email>john.doe@example.com</Email>
<PhoneNumber>+1234567890</PhoneNumber>
</Member>
<Member id="102">
<Name>Jane Smith</Name>
<Email>jane.smith@example.com</Email>
</Member>
</Library>
A possible schema would be:
<xs:schema xmlns:xs="<a href="http://www.w3.org/2001/XMLSchema"">http://www.w3.org/2001/XMLSchema"</a> elementFormDefault="qualified">
<!-- Root Element -->
<xs:element name="Library">
<xs:complexType>
<xs:sequence>
<xs:element name="Book" maxOccurs="unbounded" minOccurs="1">
<xs:complexType>
<xs:sequence>
<xs:element name="Title" type="xs:string" />
<xs:element name="Author" type="xs:string" />
<xs:element name="Year" type="xs:gYear" />
<xs:element name="Genre">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="Programming" />
<xs:enumeration value="Fiction" />
<xs:enumeration value="Non-Fiction" />
<xs:enumeration value="Science" />
</xs:restriction>
</xs:simpleType>
</xs:element>
</xs:sequence>
<xs:attribute name="isbn" type="xs:string" use="required" />
</xs:complexType>
</xs:element>
<xs:element name="Member" maxOccurs="unbounded" minOccurs="1">
<xs:complexType>
<xs:sequence>
<xs:element name="Name" type="xs:string" />
<xs:element name="Email" type="xs:string">
<xs:annotation>
<xs:documentation>Email should be unique</xs:documentation>
</xs:annotation>
</xs:element>
<xs:element name="PhoneNumber" type="xs:string" minOccurs="0" />
</xs:sequence>
<xs:attribute name="id" type="xs:ID" use="required" />
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
<!-- Unique Constraints -->
<xs:unique name="uniqueEmail">
<xs:selector xpath="Member" />
<xs:field xpath="Email" />
</xs:unique>
<!-- Referential Integrity -->
<xs:key name="memberIDKey">
<xs:selector xpath="Member" />
<xs:field xpath="@id" />
</xs:key>
</xs:schema>
Dataframes
What are data frames?
Data frames are a generalization of (normalized) relational tables allowing for (organized and structured) nestedness.
Dataframes are a way to represent data in a tabular way, with rows and columns. So we can interpret Dataframes as whatever data model we want, the main requirement is that it is valid against a certain schema that we define. Additional requirements are
- Schemas should not be valid for additional fields.
- Schemas should not allow “any” values, but some specific types (e.g. strings, int, booleans etc.). So we have some homogeneous data. A relational database is a dataframe, but the inverse is not necessarily true (dataframes can violate atomic integrity for example).
Two Advantages
Some formats are highly optimized for storing, e.g. Parquet, Avro, Root, Google’s protocol buffers. We gain space and time efficiency. As we have homogeneous rows, we can have more efficient look-ups by skipping entire rows. We can also have compression and columnar storage.
Parquet is called that way because the data is stored in a columnar fashion, grouping all the values (across objects) together when they are associated with the same key, which might remind you of the parquet floor of your living room.
The performance efficiency comes from optimization of the storage and the ability to read only the necessary columns for a specific query -> we store only column names once, instead of doing it in every field, while with JSON for instance, one would need to repeat the key many many times. Another advantage, is the constant size for a single row, that allows direct look-ups row per row, instead of using linear search.
Homogeneous vs Heterogeneous
Homogeneous are collections of documents that all follow the same data model, with the rules of typing allowed for dataframes, while heterogeneous doesn’t have this rules. Another important difference is knowing how to classify for flat and nested structures. Usually, if the data is Heterogeneous enough, then Dataframes are much more better.
Classification of data formats
We have three main categories of data formats:
- Binary: e.g. Parquet, Avro, ORC, Protocol Buffers (not CSV, JSON, XML, YAML)
- Nestedness: e.g. JSON, XML, Parquet, Avro (not CSV)
- Schema: if they need a valid data frame, e.g. Avro, Protocol Buffers, XML Schema, JSON Schema (not CSV, JSON or YAML)
Columnar Storage
Dataframes are more efficient compared to Wide Column Storage in some aspects because the keys only need to be described once, allowing us to store them efficiently. Another reason: if we only need a single column in our Apache Spark task then we could only fetch the needed column and ignore the others. In apache spark, the dataframes are stored as an internal dataframe type.
If we store nested dataframes in a relational database. This is much more difficult to process both for humans and machines. Machines need to parse again the stored string into a the correct format. Human’s need to write some weird SQL code for lateral views with explode operators.
References
[1] Codd “A Relational Model of Data for Large Shared Data Banks” Communications of the ACM Vol. 13(6), pp. 377--387 1970