Introduction to Wide Column Storages
One of the bottlenecks of traditional relational databases is the speed of the Joints, which could be done in using a merge join, assuming some indexes are present which make the keys already sorted. The other solution, of just using Distributed file systems, is also not optimal: they have usually a high latency, with high throughput, that is not optimal with the series of small files that it is optimized for. While Object Storages, do not have APIs that could be helpful -> richer logical model.
Wide Column Storage solve this problem by keeping the entire table already joined -> highly structured data, and providing similar querying abilities compared to relational tables. This brings to highly sparse relational tables.
The Usage
Wide column stores were invented to provide more control over performance and in particular, in order to achieve high-throughput and low latency for objects ranging from a few bytes to about 10 MB, which are too big and numerous to be efficiently stored as so-called clobs (character large objects) or blobs (binary large objects) in a relational database system, but also too small and numerous to be efficiently accessed in a distributed file system. ~From Chapter 6 of Big Data book
The idea here is sharding, trying to spread RDBMS into multiple machines, so that one machine has some tables, others other, one example is the famous cassandra that Discord used to scale their system.
Design principles
Two main principles guide the design of wide column stores:
- Wide sparse, joint, data tables, because the joins are the expensive operations
- Batch processing: Store together what is accessed together.
These are the current problems, with wide column stores we should solve all of these problems.
This project has originated at Google with Big Table (similarly to Big Query). HBase is an opensource equivalent of the Google projects.
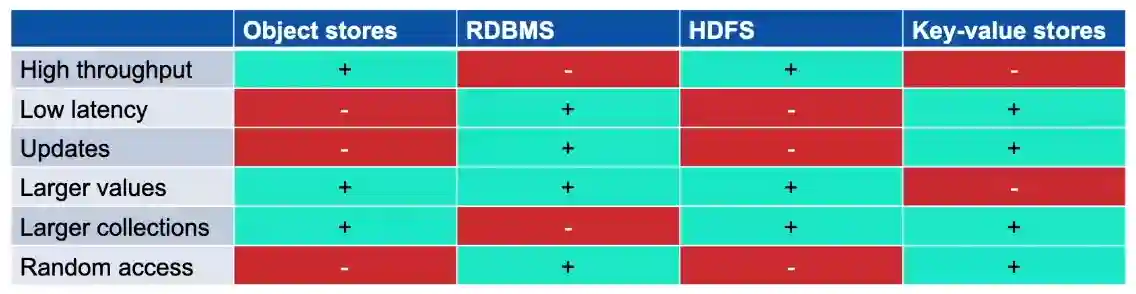
With traditional relational database management systems, the joins are the expensive part of the operations.
Wide Column Stores solve this problem by storing large sparse tables, as in the image:
Basic Characteristics
We summarize here some of the defining characteristics for Wide Column Storages:
- Support up to 10MB for files
- Sparse data model
- No Schema enforcement (difference compared to RBDMS)
- No SQL, but something lower level similar to key-value stores.
HBase
Logical Model
Row Ids and Keys
Row ids are just sequences of bits, but unlike RDBMS they are sortable, and is compound of different things, like row, column or version.
Specifically a key is composed of
- Column Family
- Row Id
- Column qualifier (name)
- Version (timestamp associated to a value).
Column Families
An intution over this new concept is the following: these could be the actual tables that would get stored if the table was normalized. These must be known in advance; it is possible to add a new family but it is an expensive operation. One can also add columns on the fly in the tables, but not column families.
Also columns have names (array of bytes, that are repeated a lot in the physical model, so they should be quite short!), not specific types as with RDBMS, those are called column qualifiers. We will see later in the physical level that both families and qualifiers are repeated in every key-value pair, which pushes towards a shorter names.
Operations
They have classical GET, POST, PUT, DELETE operations. The difference with RDBMS is that they also support range queries on the ID or timestamp for the versions, called scans, differently from object stores or key value stores.
Locks
Row updates are atomic, no matter how many row columns constitute the row-level transaction. This keeps the locking model simple.
From the Hadoop guide here.
Physical Architecture
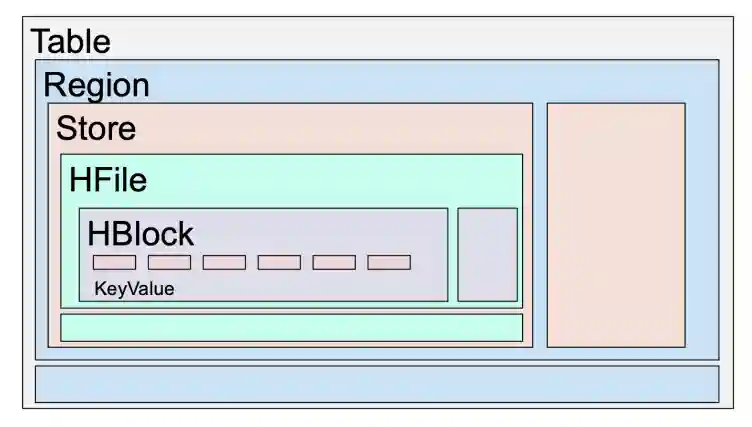 Image From the textbook.
Image From the textbook.
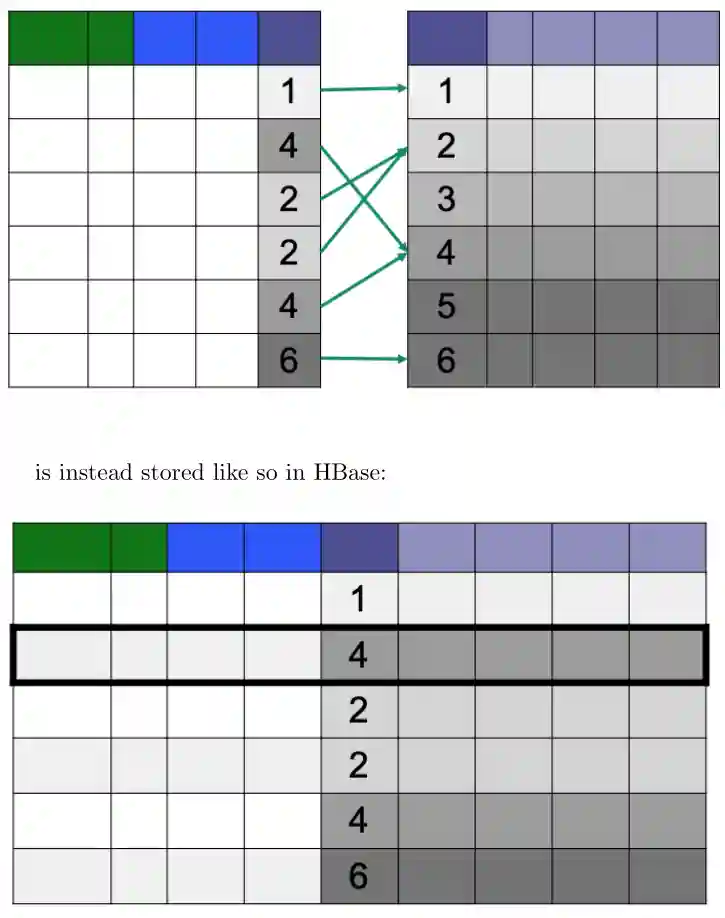
Regions and Stores
A region is just a continuous section of the rows. We define the stores which are intersections between a region and a column family. All the cells of a store are stored together. A single region is usually assigned to a RegionServer (see next section). When a region becomes too large, a RegionServer splits this region into two, and then could be rebalanced by the HMaster. The responsibility does not imply storage! This is a very important thing because the actual data is in HDFS. The responsibility is not replicated, because HDFS automatically replicates the underlying data.
On a probability point of view, all the files are going to come back to the RegionServer because RegionServers are usually going to delete and recreate files, and HDFS by default stores the first copy on the same machine it is creating it from. The nice thing is that if the hblock is in the same machine, the process can circumvent HDFS and directly read that HDFS block. This was possible because HDFS and Wide column storage has been developed by the same team. So they have nice compatibilities.
Network architecture
The network topology is the same as the one we have for Distributed file systems. We have a main node and some slave nodes. In this context they are called HMaster and RegionServers. We also have standby master nodes in this case.
The HMaster has a metatable of all the responsibilities of every RegionServer, heartbeat and reports system also here to keep track of this in a old version, before there were also race conditions, see Programmi Concorrenti. Now in order too keep the presence of everybody is something called a zoo-keeper.
Creating tables, deleting them, creating column families, all the Data Definition operations go through the HMaster. HMaster's job is to load balance the RegionServer's load in terms of quantity of data. If regions grow too big, then it can split or reorganize the regions across the servers.
HFiles and KeyValues
Stores are Memorized as HFiles, organized in HBlocks of fixed size of 64Kb (+ last key key value, so it could be a little larger), usually the key-values are read in the blocks. These blocks are then compacted together (see #Log Structured Trees) until it reaches a maximum size for a region, which is typically 10GB. When the limit is reached, the region is usually divided into two.
These files are just list of the cells, stored by coordinate (keys, often in CamelCase) and values (also different versions are stored along side each other)
A KeyValue in a HFiles is made of 4 parts:
- Key-length
- Value-length
- Key
- Value
This is a prefix code, see Algorithmic Probability for something more about prefix codes.
The HFile also contains the boundary index of all the blocks that it has. So that it is easy to check for membership inside the blocks
Structure of Key and Values
One also has an index, idea similar from b-trees, so the lookup inside a HDFS block is easy.
This image from the book cleanly summarizes the structure of the Key:
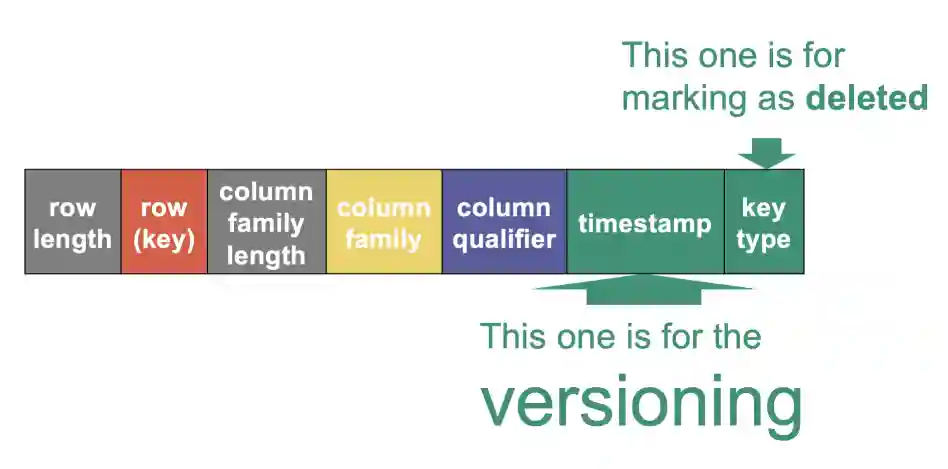
The red part of the key is of variable length. Grey boxes are of fixed length, also column family. The qualifier is variable, but you can recover that by knowing the length of the whole key.
In memory key-value store
We store the key values in order in memory using some sort of tree. The upside is that we don't need to cancel and recreate the block in HDFS, because that only allows appending, the written data is not modifiable. When the RAM store is full, then we flush the memory down to an HFile. When we flush we have a linear merge and we store the new file in this way.
We have three cases when the flush happens:
- Write-ahead log is full
- Memstore size if sull
- Max memstore for a single store
Write-Ahead log
This is a log to keep the changes done in the RAM, so that we don't lose things after a crash. Appending is ok in HDFS, so it's quite compatible with the underlying system. -> Every write is first written in this log file before being put in the RAM. This is similar to the EditLog in HDFS.
Log Structured Trees
These structures attempt to optimize for throughput, the B-Trees are optimized for latency. As every id is sorted by key, it's easy to merge the HFiles together, we just need to use the Merge function, the same for MergeSort algorithm.
Compaction
This is a process that merges many HFiles together when you have too many HFiles because of the flushes. The compaction process is still a linear process because the key values stores are linear. Merging two HFiles usually is makes the system faster for reads because we don't need to search anymore for all all the mini files that the system creates after the memstore is full. By default HFiles have a maximum size of 10GB (this is the max size after compactions I suppose). If it gets bigger, then the region might be splitted.
This is usually triggered when:
- The number of files is above a certain threshold.
- Or it might follow a 2048 game rule by merging HFiles with the same size (this is what the Professor has explained).
Optimization of HBase
Lookup tables
In order to know which RegionServer a client should communicate with to receive KeyValues corresponding to a specific region, there is a main, big lookup table that lists all regions of all tables together with the coor dinates of the RegionServer in charge of this region as well as additional metadata.
So, just lookup tables that are known by everybody, and this should make communication a little bit faster.
Cache Usages
We should not use cache when we have random access or when we are doing batch processing, because the data the batches are processing are usually separate and independent with each other. You should refer to Memoria and Memoria virtuale to know how usually is cache made.
Key Ranges
Efficiently tells for sure that a Key range is not contained in a file.
So they are just some small optimizations, which at the end make HBase quite fast.
Bloom Filters
It is basically a black box that can tell with absolute certainty that a certain key does not belong to an HFile, while it only predicts with good probability (albeit not certain) that it does belong to it.
So that we can skip over files so that we can fasten the lookup time. Without bloom filters we would look for a specific key value in every single HFile, which could be quite slow.
See Bloom Filters for an overview on how they work.
Data locality and Short Circuiting
We have specified in some paragraphs before that when HBase writes a HFile to a node, the first replica of the file is written on the same node. This allows for short circuiting which allows to directly read from the disk without asking the NameNode for the classical HDFS system.