Language Constituents
A constituent is a word or a group of words that function as a single unit within a hierarchical structure
This is because there is a lot of evidence pointing towards an hierarchical organization of human language.
Example of constituents
Let's have some examples: John speaks [Spanish] fluently John speaks [Spanish and French] fluently
Mary programs the homework [in the ETH computer laboratory] Mary programs the homework [in the laboratory]
These sentences can be swapped without problem with each other. These group of words work like a single unit.
Ambiguity
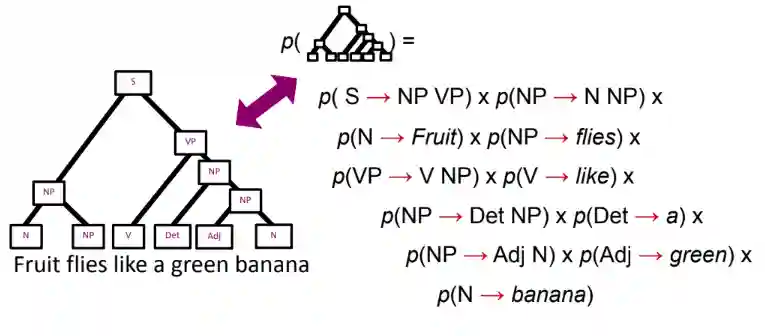
We expand on the first notions of ambiguity of natural language introduced here. We can see that ambiguous sentences have different constituents. Here is an example: [Fruit flies] [like [a green banana]] or Fruit [flies [like [a green banana]]]
Sources of ambiguity are
- attachment: I [shot [an elephant] [in my pajamas]] vs. I [shot [an elephant [in my pajamas]]]
- modifier scope [[plastic cup] holder] vs. [plastic [cup holder]] (Is it a holder for plastic cups or a cup holder made of plastic?)
- Others that are not treated here. Having different parse trees correspond to different consituents! The main idea is to create a probability distribution over possible parse trees, as some are more probable than others, then learn this distribution from data.
Binding
This is the analogous for natural language. We have studied these in many different settings: analysis of programming languages Nomi e Scope, logic Logica del Primo ordine and operative systems Paginazione e segmentazione. TODO: explain in the context of natural languages.
Context-Free Grammar extensions
We first introduced context free in these documents Descrizione linguaggio and Linguaggi liberi e PDA. Here we expand on a probabilistic version to model the likeliness of a given parse of an ambiguous structure.
Probabilistic Context-Free Grammars
The easiest way to extend this is to assign a probability to each production. After we have this, then the probability of a given three is just the product of all the production probabilities. This is a easy and natural way to extend the classic notion of derivation trees.
PCFG are Locally Normalized
This is easy because given some production rules we have that
Which mean for a single non-terminal, we would like that the sum of the probabilities of the productions is one, i.e. it is not leaked elsewhere. This is the same idea presented in Language Models.
Weighted CFGs
Instead of assigning a probability, we just add a weight to each of the production. In this case, what is important is the relative weight of the productions.
Then we can use the same idea in Log Linear Models to put them back into a probability space. This is easier as we just need to assign a score over the productions, and not a probability.

WCFGs are Globally Normalized
WCFGs are structured Softmax Function because given a tree we have that
The difficult thing here is to compute the normalizing constant because can be infinite:
For some grammars the normalizer could also diverge For example with the grammar has infinite derivations of the same string , but there are infinite ones.
Normalized Grammars
We solve this problem by converting the grammar into a Chomsky Normal Form (see Semplificazione grammatiche#Chomsky Normal Form). In this case the number of possible trees is no longer infinite, but around , which is the number of rooted binary trees, which follows Catalan Numbers for some reason unknown to me. One interesting observation, is that the number of rooted binary trees of nodes has Catalan number We lose the original structure of our tree but we gain on the possibility of computing the normalizer.
In this manner we can compute the probability of having a certain parse tree , given a sentence as follows:
We have effectively splitted the score in two parts, one for the non-terminal and one for the terminal. The normalizer is just the sum over all possible trees for a given sentence.
The CKY parser
Introduction to CKY
The Cocke–Kasami–Younger Algorithm provides an efficient way to compute the normalizer for a CNF grammar, in , with length of our sentence and size of the rule-set of the CNF. Originally this algorithm has been developed for a classical recognition problem: given a string, recognize if the grammar accepts it. Goodman wrote a paper generalizing the algorithm to arbitrary semirings. Humans parse in linear time usually perhaps: they don't need to rehearse and go back in the string. There could be local patches where humans are non-linear (i.e. they go back and try to make sense of it), but mostly a
See wikipedia for the pseudocode of the algorithm.
The Algorithm
This is another dynamic programming algorithm. Originally, it has been used to compute the normalizer for a WCFG, but then it has been generalized by Goodman (1999) to arbitrary semirings. This allows to compute different things like
- Best parse tree
- Entropy of parse tree distribution
- Normalizing constant (its the case we are interested in)
 Let's analyze this algorithm in detail.
We need a WCFG, a score function for each production rule, and a sentence for which we want to compute the normalizer for the parsing trees.
We first initialize the base of our dynamic programming table with the scores of the terminal rules.
Then we iterate over the length of the sentence, and for each cell we iterate over the possible splits of the sentence in two parts, and we check if the two parts can be generated by the non-terminal in a span (a contiguous substring). If they can, then we add the score of the rule to the score of the cell.
Let's analyze this algorithm in detail.
We need a WCFG, a score function for each production rule, and a sentence for which we want to compute the normalizer for the parsing trees.
We first initialize the base of our dynamic programming table with the scores of the terminal rules.
Then we iterate over the length of the sentence, and for each cell we iterate over the possible splits of the sentence in two parts, and we check if the two parts can be generated by the non-terminal in a span (a contiguous substring). If they can, then we add the score of the rule to the score of the cell.
This algorithm can be visualized in the following diagram:
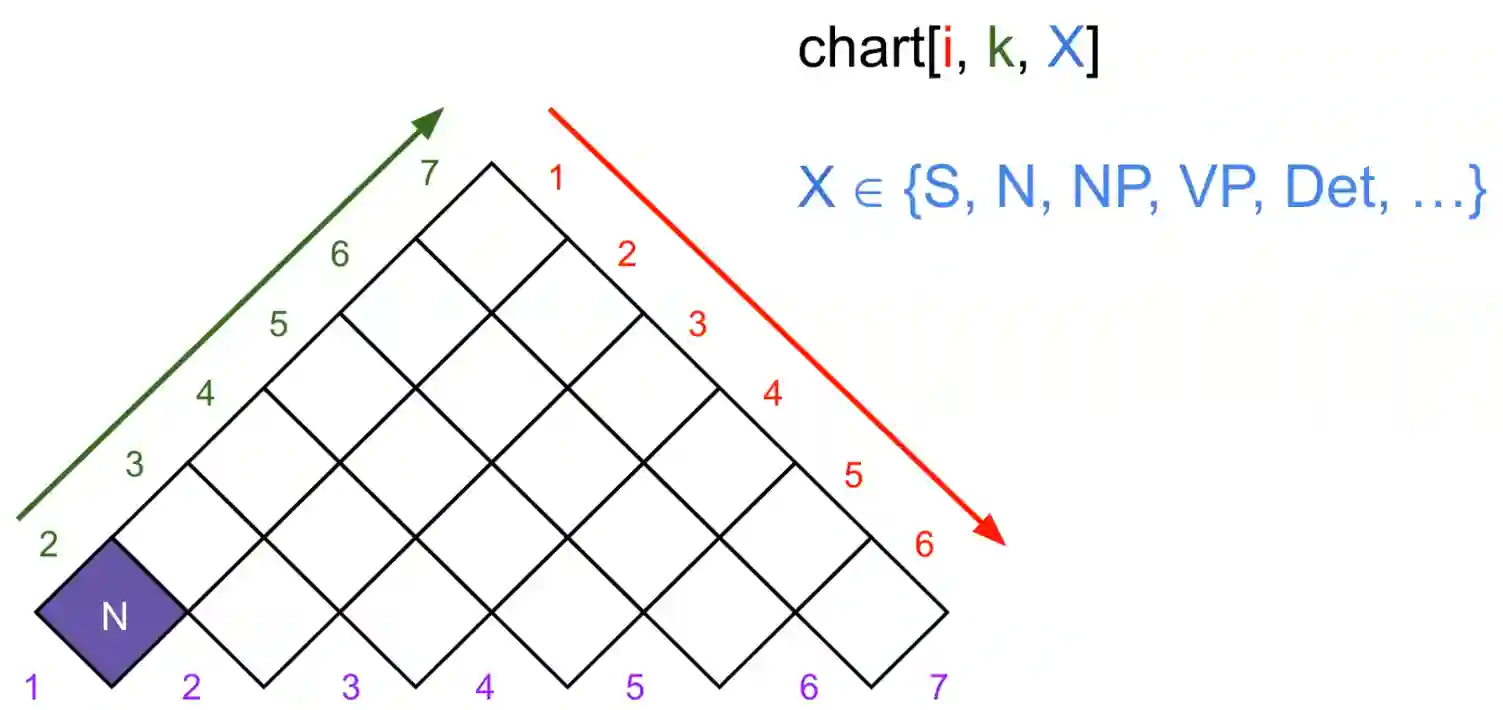 It is a little weird for the count starts, but other than that it is quite intuitive.
It is a little weird for the count starts, but other than that it is quite intuitive.