Questo è stato creato da 1948 Shannon in (Shannon 1948). Questa nozione è basata sulla nozione di probabilità, perché le cose rare sono più informative rispetto a qualcosa che accade spesso.
Introduction to Entropy
The Shannon Information Content
$$ h(x = a_{i}) = \log_{2}\frac{1}{P(x = a_{i})} $$We will see that the entropy is a weighted average of the information, so the expected information content in a distribution.
Kolmogorov complexity è un modo diverso per definire la complessità. Legato è Neural Networks#Kullback-Leibler Divergence.
We can model the classical view of entropy as the from [^1]
$$ H(\mathcal{X}) = - \sum_{x \in \mathcal{X}, P_{\mathcal{X}}(x) > 0} p(x)\log(p(x)) \tag{1.1} $$Expected value of Surprisal which is the uncertainty of a random variable $X$ taking a certain value which is $p(X = x) = P(x)$, but we want to measure it using log-likelihood.
Ossia, possiamo dire in modo intuitivo quanto sarebbe sorprendente vedere che si avverasse quell’evento.
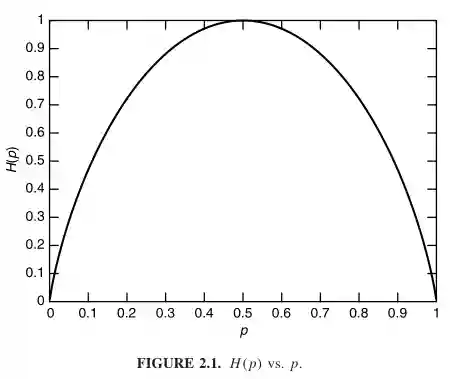 This is the graph for the binary case:
$$
H(\mathcal{X}) = p\log \frac{1}{p} + (1- p) \log \frac{1}{1 - p}
$$
$$
\begin{align*}
H(X) := E[I(X)] &= \sum_{i=1}^n P(x_i)I(x_i) \\
&= \sum_{i=1}^n p_i \log(1/p_i) \\
&= -\sum_{i=1}^n p_i \log(p_i) \tag{1.2}
\end{align*}
$$
This is the graph for the binary case:
$$
H(\mathcal{X}) = p\log \frac{1}{p} + (1- p) \log \frac{1}{1 - p}
$$
$$
\begin{align*}
H(X) := E[I(X)] &= \sum_{i=1}^n P(x_i)I(x_i) \\
&= \sum_{i=1}^n p_i \log(1/p_i) \\
&= -\sum_{i=1}^n p_i \log(p_i) \tag{1.2}
\end{align*}
$$Axiomatic Approach to Entropy
We can define the entropy as the only function that satisfies the following properties (the function is commonly called surprise):
- $H(X) \geq 0$ for every discrete r.v. which is related to the code length, which we don’t want to be negative
- $H(X, Y) = H(X) + H(Y)$ when $X, Y$ are independent random variables.
- $H(X) \text{ is maximal }$ when $X \sim Unif(0, 1)$ this concept is related to hard to guess the results.
Properties of the entropy
One observation is that labels don’t matter, we just need the probability vector and don’t care about what it represents.
The entropy is always positive. It’s easy to prove because all probabilities are $0 < p \leq 1$ so every term in the sum is positive because log in that interval is also positive.
Axiomatic approach
One could derive the entropy from an axiomatic point of view, with the idea of Surprise We just need three requirements: Given a probability space $\Omega, \mathcal{A}, \mathbb{P}$ , then the surprise of an even $E \subseteq \mathcal{A}$ is equal to a function $S([\mathbb{P}(E)])$ which satisfies the following properties:
- $S(1) = 0$
- $S$ is continuous
- $S$ is monotonic decreasing, meaning that if $p > q$ then $S(p) < S(q)$
- $S$ is additive, meaning that $S(pq) = S(p) + S(q)$ when $p, q$ are independent.
The entropy is just the expected value of the surprise.
Chain Rule
$$ H(X, Y) = H(X) + H(X|Y) $$$$ H(X_{0}, X_{1}, \dots, X_{i}) = \sum_{i}H(X_{i}|X_{i-1}\dots X_{0}) $$Upper bound
$$ H(X) \leq \log \lvert \mathcal{X} \rvert $$Con $\mathcal{X}$ l’insieme immagine della variabile aleatoria discreta $X$. Importante in questo caso che la nostra variabile sia discreta, altrimenti il teorema provvisto in (Cover & Thomas 2012) 2.6.4 non funziona. Non è molto banale l’idea di utilizzare la uniforme per modellare il numero di elementi. e usare la positività di KL per finire l’upper bound.
$$ P_{X}(x) = \frac{1}{\lvert \mathcal{X} \rvert } $$$$ \sum P_{X}(x) \log \frac{1}{P_{X}(x)} = \log \frac{1}{P_{X}(x)} = \log \lvert X \rvert $$$$ \sum P_{X}(x) \log \frac{P_{X}(x)}{\frac{1}{\lvert \mathcal{X} \rvert }} = \sum P_{X} \log P(x) + \sum P_{X}(x) \log \lvert \mathcal{X} \rvert = \log \lvert \mathcal{X} \rvert - H(X) $$$$ \log \lvert \mathcal{X} \rvert - H(X) \geq 0 $$Which ends the proof.
Entropy is concave
Uso l’upper bound e il fatto che KL è convesso per dimostrare questa cosa.
Functional dependency
Non fare Se $Y = f(X)$ per qualche funzione, allora $H(Y|X) = H(X|Y) = 0$ si può risolvere con qualche ragionamento sul supporto di entropia. Interessante vedere che ha una piccola relazione con Normalizzazione dei database#Dipendenze funzionali.
Monotonicity of Entropy
$$ H(X) \geq H(X \mid Y) $$It is also called the principle Information never hurts meaning you are never more uncertain about a random variable when you have more information about it.
$$ H(X) - H(X \mid Y) = \sum P(x) \log P(x) - \sum P(x, y) \log P(x \mid y) = \sum P(x, y) \log \frac{P(x, y)}{P(x)} \underbrace{\geq}_{\text{Jensen}} 0 $$This is also the reason why mutual information is always positive.
Types of entropy
Conditional Entropy
$$ H(Y|X) = \sum_{x \in \mathcal{X}}p(x) H(Y|X=x) = \sum_{x \in \mathcal{X}, y \in \mathcal{Y}} p(x, y) \log \frac{1}{P(y|x)} = \mathbf{E}\left[ \log\frac{1}{p(Y|X)} \right] $$La nozione con il valore atteso è la più semplice anche in questo caso.
$$ H(Y \mid X) = \mathbb{E}_{(x, y) \sim p(x, y)}\left[ \log \frac{1}{p(y \mid x)} \right] $$conditional entropy corresponds to the expected remaining uncertainty in $Y$ after we observe $X$
Joint Entropy
$$ H(X, Y) = - \sum_{x, y} p(x, y) \log p(x, y) $$$$ H(X, Y) = H(X) + H(Y \mid X) = H(Y) + H(X \mid Y) $$Relative Entropy or Kullback-Leibler
Let’s take $\lvert \mathcal{X} \rvert < \infty$, and take distributions P, Q, $\mathcal{X} \to \mathbb{R}$ such that $p(x) \geq 0 \forall x \in \mathcal{X}$ and the sum is 1, same thing for $Q$, then we define the Kullback-Leibler Divergence between those distributions to be
$$ D(P \mid \mid Q) = \sum_{x \in \mathcal{X}} P(x) \log \frac{P(x)}{Q(x)} $$We need to define some corner cases:
- If $P(x) = 0$ and $Q$ is anything then its 0
- If $\exists \xi \in \mathcal{X}$ such that $P(\xi) > 0$ and $Q(\xi) = 0$ => $D(P \mid \mid Q) = + \infty$.
- If $P \ll Q$ then $D(P \mid \mid Q) < \infty$ (I did not understand why)
This has some relations with the entropy, we can use some log properties and have the following result:
$$ D(P \mid \mid Q) = - H(P) - \sum P(x) \log Q(x) $$The second addendum can be called cross-entropy.
In modo praticamente equivalente possiamo definire una versione condizionata. e si può applicare anche in questo caso una chain rule
$$ DL(P(x, y) \mid\mid Q(x, y) = DL(P(x) \mid\mid Q(x)) + DL(P(x|y) \mid\mid Q(x|y)) $$Relative entropy is not a distance not a metric, so its incorrect to say it is a distance, but for practical purposes it seems to work well: if the Relative entropy is small also the probability vectors are small.
KL is positive or null
$$ DL(P \mid\mid Q) \geq 0 $$Con uguaglianza se hanno esattamente la stessa distribuzione. We have that $D(P \mid \mid Q) = 0 \iff P = Q$ .
E ricordandoci che $\log$ è una funzione concava, quindi si può utilizzare Jensen. Lo dimostriamo ora in breve. Sappiamo che la funzione $-\log(x) = \log\left( \frac{1}{x} \right)$ è una funzione convessa, perché il negativo di una funzione concava, che è il logaritmo.
Allora consideriamo $\frac{1}{u} = \frac{Q(x)}{P(x)}$ che è la parte dentro al logaritmo perché così possiamo usare Jensen Allora comunque abbiamo
$$ \sum_{x} P(x) \log\left( \frac{Q(x)}{P(x)} \right) \geq \log\left( \sum_{x} P(x) \cdot \frac{Q(x)}{P(x)} \right) = \log(1) = 0 $$$$ D_{KL}(P \mid \mid Q) \geq 0 $$In modo facile.
KL is convex
$DL(p\mid\mid q)$ è convesso sulla coppia $(p, q)$, 2.7.2 di (Cover & Thomas 2012). Anche sula 2.26 di McKay è buono, anche se non esattamente parla di questo.
Mutual information
Questa nozione definisce quanta informazione hanno in comune due variabili aleatorie
Definizione
$$ I(X;Y) = \sum_{x}\sum_{y} p(x, y) \log\left( \frac{p(x, y)}{p(x)p(y)} \right) = H(X) - H(X|Y) $$Si può fare dopo un po’ di calcoli che qui ho omesso, ma non dovrebbe essere difficile farlo.888
Si può intendere la mutual information anche come KL fra le distribuzioni $p(x, y)$ e $p(x)p(y)$ si può notare che queste due sono uguali quando le due sono indipendenti, che è coerente con la nostra nozione che abbiamo dell’indipendenza.
Proprietà
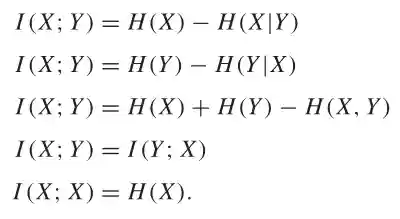
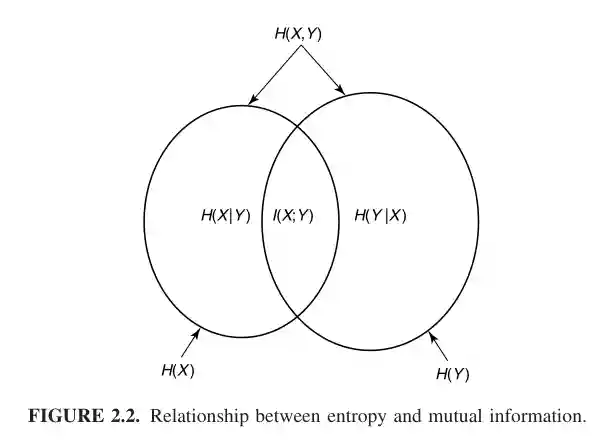 Another property:
$$
I(X; Y\mid Z) = I(X ; Y, Z) - I(X ; Z)
$$
Another property:
$$
I(X; Y\mid Z) = I(X ; Y, Z) - I(X ; Z)
$$
Redundancy and Synergy
$$ I(X;Y;Z) = I(X;Y) - I(X;Y\mid Z) $$Then synergy between $Y$ and $Z$ is present when the interaction information is negative, and redundant when its positive. This is because, intuitively, if it is negative it means $Z$ can provide more information with $Y$ about $Z$, else, they both have some information about $X$ which is probably not enough.
Example: Independent Variable in MI
We see that if $Y \mid X \perp Z$ then $I(X;Z) = I(X, Y; Z)$ this means then that the relation between $Y$ and $Z$ is neither redundant or synergic
$$ \begin{align} I(X, Y; Z) &= \mathbb{E}\left[ \log \frac{P(X, Y, Z)}{P(X, Y) P(Z)} \right] \\ &= \mathbb{E}\left[ \log \frac{P(X, Z)}{P(X) P(Z)} \right] + \mathbb{E}\left[ \log \frac{P(Y \mid X, Z)}{P(Y \mid X)} \right] \\ &= I(X; Z) + \mathbb{E}\left[ \log \frac{P(Y \mid X, Z)}{P(Y \mid X)} \right] \\ &= I(X; Z) \end{align} $$Where in the last step we used the fact that $Y \perp Z \mid X \implies P(Y \mid X, Z) = P(Y \mid X)$.
This means that if the independence condition is satified, then we can add random variables as we like without changing the mutual information.
Sufficient Statistics
Possiamo rappresentare il sampling da una certa famiglia di distribuzioni $f_{\theta}(x)$ , rappresentato da $X$, e una sua statistica a caso (media varianza etc, che credo basti una funzione sul valore) come T, allora possiamo rappresentarlo come una Markov Chains#Catena di 3 variabili $\theta \to X \to T(X)$ E vale il teorema di information processing
$$ I(\theta; T(X)) \leq I(\theta; X) $$Si può chiamare una statistica per $\theta$ sufficiente se $X$ contiene tutta l’informazione di $\theta$. Non so bene cosa significhi. La cosa importante è che la statistica sufficiente preserva la mutua informazione ossia si ha una uguaglianza in quella relazione di sopra. Vedere 2.9 di (Cover & Thomas 2012) per esempi .
Questa cosa potrebbe permettere di dire che usando quella statistica io posso dimenticarmi del parametro, perché riesco a ricavarmelo senza problemi credo….
The purpose of sufficiency is to demonstrate that statistics that satisfy this property do not discard information about the parameter, and as such, estimators that might be based on a sufficient statistic are in a sense “good” ones to choose.
Da https://math.stackexchange.com/questions/1186645/understanding-sufficient-statistic. Sufficient statistics also have a quite nice relationship with The Exponential Family.
Fano’s inequality
L’idea principale è utilizzare una variabile aleatoria per stimarne una altra, usando l’entropia condizionale fra le due.
Enunciato Fano
$$ H(P_{e}) + P_{e}\log \lvert \mathcal{X} \rvert \geq H(X|\hat{X}) \geq H(X|Y) $$$$ 1 + P_{e} \log \lvert \mathcal{X} \rvert \geq H(X|Y) $$Dimostrazione Fano
Questa è una bomba da fare. Poi però ha un sacco di conseguenze non applicabili in modo immediato (cioè non ci arrivi subito se non le fai un po’ prima).
Maximum Distribution entropy
Un problema classico nella teoria dell’informazione è trovare la distribuzione che massimizzi l’entropia (quindi l’informazione contenuta credo) dati certe conoscenze a priori, Ossia data una funzione $f$ e certe condizioni che deve rispettare, massimizzare l’entropia.
SI può dimostrare (lo si può vedere da una reference di sopra) che la distribuzione che massimizza l’entropia, avendo solamente la condizione di probabilità, ossia che $\sum_{x}p(x) = 1$ è la distribuzione uniforme. Mentre se assumo anche media $\mu$ e varianza $\sigma^{2}$ allora è la gaussiana (dimostrato in Maximum Entropy Principle. In un certo senso possiamo dire che queste distribuzioni sono molto ricche di informazioni.
Codewords
Jensen’s Inequality
$$ f\left( \sum_{i} \lambda_{i} x_{i} \right) \leq \sum_{i}\lambda_{i}f(x_{i}) $$Con $\sum_{i}\lambda_{i} = 1$. Questa cosa si estende in modo molto semplice a variabili aleatorie e $E$ quando al posto di $\lambda_{i}$ mettiamo una probabilità in un punto.
La dimostrazione non dovrebbe essere molto difficile. La strategia è utilizzare l’induzione in modo abbastanza classico. Non so in che modo si estende su funzioni continue, ma quelle sono cose tecniche matematiche non interessantissime.
Log sum inequality
$$ \sum_{i=1}^{n}a_{i} \log\left( \frac{a_{i}}{b_{i}} \right) \geq \left( \sum_{i=1}^{n}a_{i} \right)\log \frac{\left( \sum_{i=1}^{n} a_{i} \right)}{\sum_{i=1}^{n}b_{i}} $$Con uguaglianza se vale che $\forall i, \frac{a_{i}}{b_{i}}= const$
Krafts Inequality
https://en.wikipedia.org/wiki/Kraft%E2%80%93McMillan_inequality Questo teorema interessa cose dei codewords, perché ci interessano dei set di prefixfree che sono molto più gestibili probabilmente dal punto di vista dell’interpretazione. La cosa interessante è:
$$ \sum_{x} 2^{-l(x)} \leq 1 $$Il motivo è abbastanza semplice, questo si spiega in modo grafico in maniera praticamente immediata quando facciamo il disegno.
Si può vedere dall’albero binario corrispondente di un insieme di set binari con prefissi che se un parente è scelto (colorato nel disegno), allora nessun discendente può essere scelto perché altrimenti avresti un prefisso. Inoltre se colori quelli sopra, significa che al massimo se sommi tutti quei valori otterrai 1 sse hai utilizzato tutti i rami a tua disposizione (meaning, che non puoi scegliere altri code-work, altrimenti perdi la prefix property).
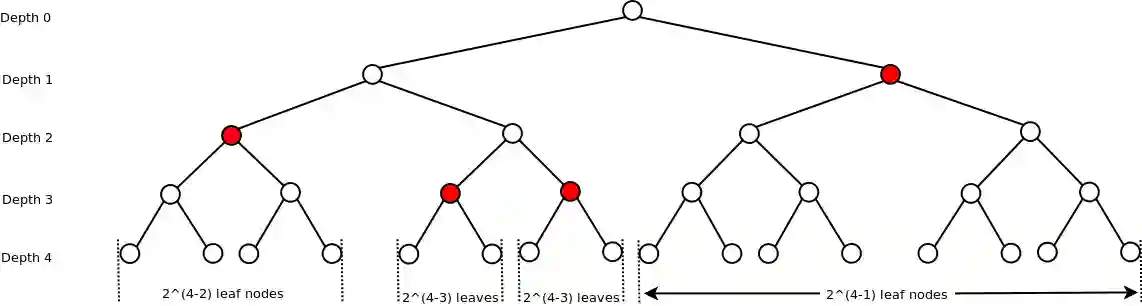
Source coding theorem for symbol codes
$$ H(P) \leq L \leq H(P) + 1 $$Ossia la lunghezza migliore possibile è boundata da valori di entropia. Che è una cosa abbastanza forte perché relaziona come deve essere fatto il code-words, con la complessità dell’informazione che vogliamo andare a utilizzare. La dimostrazione non la facciamo qui, ma è fattibile con le tue conoscenze credo, ti serve la Gibbs inequality qui sotto per una freccia
$$ L = \sum_{x} p(x) l(x) = \sum_{x} \left( p(x) \log\left( \frac{1}{q(x)} \right) \right) \geq \sum_{x}p(x) \log\left( \frac{1}{p(x)} \right) =H(x) $$Dove abbiamo usato anche l’ineguaglianza di Gibbs #Gibbs Inequality e il fatto che vale #Krafts Inequality.
$$ l_{i} = \lceil -\log_{2}(p_{i}) \rceil $$$$ L = \sum_{x} p(x) l(x) = \sum_{x} p(x) \lceil -\log_{2}(p_{x}) \rceil \leq \sum_{x}p(x) \left( \log_{2}\left( \frac{1}{p(x)}\right) +1 \right) = H(x) + 1 $$Una nota interessante è questo teorema ci permette di definire un concetto di efficienza di rappresentazione. Tutto quanto dato da KL divergence è una specie di inefficienza.
$$ L = H(x) + D_{KL}(P \mid \mid Q) $$Con $Q$ la probabilità associata alle singole codewords, assumendo che siano uniformi e simili per dire.
Gibbs Inequality
$$ \sum_{x} P(x) \log\left( \frac{1}{P(x)} \right) \leq \sum_{x} P(x) \log\left( \frac{1}{Q(x)} \right) $$Qualunque sia l’altra distribuzione. Si può dimostrare in modo abbastanza diretto utilizzando il fatto che la Kullback-Leibler divergence, presentato in Neural Networks, è sempre positiva o uguale a 0. Infatti la parte di sopra si può riscrivere come
$$ -\sum_{x} P(x) \log\left( \frac{P(x)}{Q(x)} \right) = D_{KL}(P \mid \mid Q) $$Language Models
Entropy Rate is not Constant
Paper: Braverman et al. (2020) - “Calibration, Entropy Rates, and Memory in Language Models” This seminal ICML 2020 paper provides definitive empirical evidence against entropy rate constancy.
Key Finding: State-of-the-art language models exhibit dramatic entropy rate amplification during generation.
Empirical Evidence:
| Model | Test Perplexity | Generated Text Perplexity |
|---|---|---|
| AWD-LSTM (PTB) | 58.3 | 93.1 |
| CNN-LSTM (GBW) | 29.8 | 49.4 |
| Transformer (GBW) | 28.1 | 34.7 |
| GPT-2 (WebText) | 23.7 | 61.2 |
Interpretation:
- Test perplexity measures the model’s one-step prediction accuracy
- Generated text perplexity measures exp(entropy rate) of the model’s own generations
- The gap shows that entropy rate increases dramatically over time during generation
- For GPT-2: entropy rate grows from ~23.7 to ~61.2 (2.6x increase!)
2.2 Visual Evidence
The paper shows perplexity curves (exp of conditional entropy) over generation time:
- At t=1: Model’s upper bound for language perplexity (test set performance)
- As t→∞: Exponential of the entropy rate of the model’s generations
- Result: Curves drift upward monotonically, not flat
For a perfectly calibrated model, these curves should be flat (constant entropy rate). Instead, they show systematic upward drift.
References
[1] Li & Vit{\'a}nyi “An Introduction to Kolmogorov Complexity and Its Applications” Springer International Publishing 2019
[2] Shannon “A Mathematical Theory of Communication” The Bell System Technical Journal Vol. 27, pp. 379--423, 623--656 1948
[3] Cover & Thomas “Elements of Information Theory” John Wiley \& Sons 2012