At the time of writing, the compute requirements for machine learning models and artificial intelligence are growing at a staggering rate of 200% every 3.5 months. Interest in the area is being quantified as 10k papers per month on the topic, while dollar investments on compute (energy, cooling, sustainability of compute in general) have had a hard time keeping up with the continuous new requests.

Image from here
This is the general pipeline of model development, training, and inference.
One note is that the real ML code in this systems is very small, see (Sculley et al. 2015), there are massive maintenance costs in common ML systems.
Data Curation
Collection and Cleaning
Garbage in -> Garbage out ~old wisdom
The first part of every machine learning system is collect and curate good quality data. Work in this part of building machine learning systems mostly consist in:
- Aggregating data
- Identifying correct sources of the data
- Remove not good data, labeling it so that it has high quality, and similar.
- Identify anomalies/outliers, and filtering it. Very difficult to distinguish from noise.
- Fill empty values
- Having correct labels (e.g. (Deng et al. 2009) initial big effort, which is very expensive)
Analyzing preprocessing costs
We need to distinguish from online and offline preprocessing requirements. These functions will use lots of resources on the CPU and often become part of the bottleneck (see here), from personal statistics, it was about 30% just for data preprocessing. Sometimes, it also consumes more data than the training itself! The professor Ana Klimovic shows how scaling the preprocessing and training client can speed up sometimes by 100x in some cases, see here.

Image from the course slides
Model Development
In this section, we want to build a nice model for our problem, design new architectures, tune hyperparameters, and validate the accuracy. There is not so much from the system side that can be said about model development; this is another area of research.
Automated searches
This is somewhat similar to what fast performance optimization community has done with LAPACK, BLAS, see Fast Linear Algebra.
We have: Model search:
- Explore automatically different architectures to find the best one, obviously very performance intensive.
- Neural Architecture Search, where you could also use things like RL to find the best one.
Hyper-parameter tuning:
- Search for the best hyperparameters for a model
- batch size, learning rate, number of layers, activation fucntions, optimizers, and other similar things that could be considered to tune this aspect.
Training Pipeline
The training pipeline is the output of the model development phase. If you do not track all the dependencies, you wont be able to do things like this:
- Retrain models with new data
- Track data and code for debugging
- Capture dependencies for deployment
- Audit training for compliance (e.g., data privacy policies)
Then it would also enable for validation and versioning and usually does not need lot of expertise in machine learning, this is the MLOps side of things.
Usual Training Stages
After (Bommasani et al. 2022), we mostly train big ML models and then:
- Pretrain: we train the model on a large dataset, usually unsupervised, to learn general features of the data.
- Fine-tune: we train the model on a smaller dataset, usually supervised, to learn specific features of the data.
- Alignment: we train the model to align its behavior with human values and preferences or based on some reliability metrics.
Continual Training
Usually models need to be retrained to
- Include new data
- Adapt do domain shifts or data shifts
- E.g. hairstyle, fashion shifts.
- Data deletion
- E.g. GDPR, or similar laws. This means you need to incorporate new training methods starting from an existing one. It is probably difficult to balance different tradeoff, from accuracy to reliability and compliance.
For example some threshold to trigger retraining to check for concept drifts. And this would then enable for data selection policies to take the correct data for retraining. See (B{"o}ther et al. 2025).
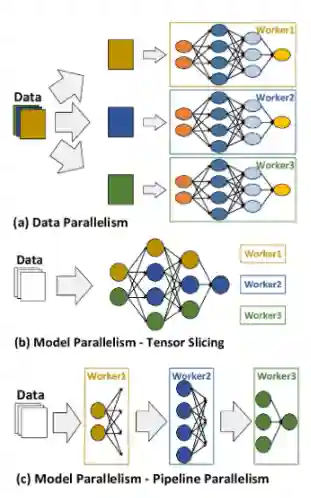
Training Parallelization
Training is one of the most compute intensive parts of the machine learning pipeline. We need to distinguish the data itself with the parameters data (weights of the model most of the time, or hyperparameters and similar things).
Data parallelism: partition the data and run multiple copies of the model, which synchronize to exchange model weight updates.
About model parallelism:
- Tensor Parallelism: we divide layer inference across nodes
- Pipeline Parallelism: We divide models across nodes.
Parameter Server
This is a classical way to implement distributed training.
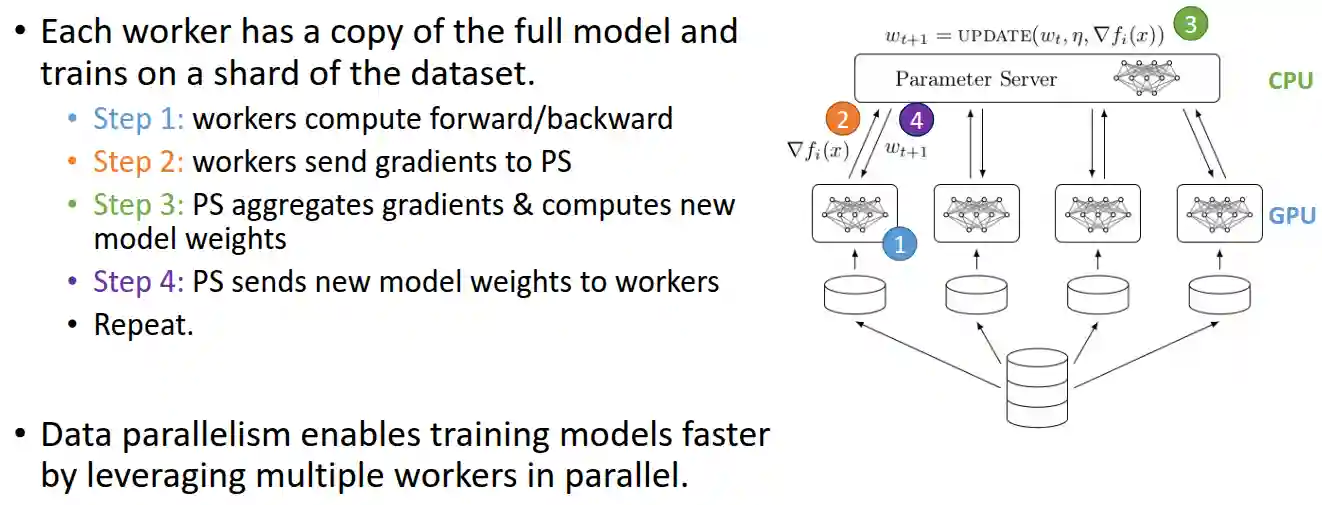
Basically, every worker has a copy of the model, and they send the gradients to the parameter server, which then aggregates them and sends them back to all workers. This is a good way to implement distributed training, but it has some drawbacks:
- The parameter server can become a bottleneck, especially if there are many workers.
- The parameter server can become a single point of failure, which can be problematic if it goes down.
AllReduce Parallelism
<a href="/Here@niruthiha2000/allreduce-explained-the-key-to-efficient-distributed-training-2cbbcc871832">https:/medium.com/ is a post explaining the all-reduce parallelism.
This is a way to implement distributed training, the GPUs share the exchange directly with each other and gradient aggregation is done across workers.
This is the most common way to implement GPU GPU interconnect thanks to fast networks between GPUs.

Reduce-Scatter phase of an all-reduce parallelism
Next phase is just gathering the weight together so that each worker has the same weights.
Each node sends $n - 1$ messages to other nodes and receives $n - 1$ messages from other nodes, where $n$ is the number of nodes, in both stages.
The total amount of data transferred: $2 × (N−1) × (K/N) = 2K × (N−1)/N$. In NVIDIA systems, we use NCCL for these kinds of communications.
Pipeline Parallelism
Due to data dependencies, it is usually difficult to have high hardware utilization with the standard forward and backward version. This form of parallelism is also called model parallelism.
pipeline parallelism partitions the layers of a model into multiple stages and distributes them across the GPUs. While training, two consecutive pipeline stages exchange intermediate activations or gradients with point-topoint communication. Since the point-to-point communication of pipeline parallelism adds small overheads compared to the synchronization of tensor parallelism, the pipeline parallelism degree can increase along with the model size. From (Kim et al. 2023) paper.
Using micro-batches, you can improve the utilization of the hardware, it is like pipelining, see Central Processing Unit, but on a different level. Introduced in (Huang et al. 2019). Pipeline parallelism might suffer from stalls (bubbles) due to dependencies and load imbalance between the devices (imbalanced partitioning).
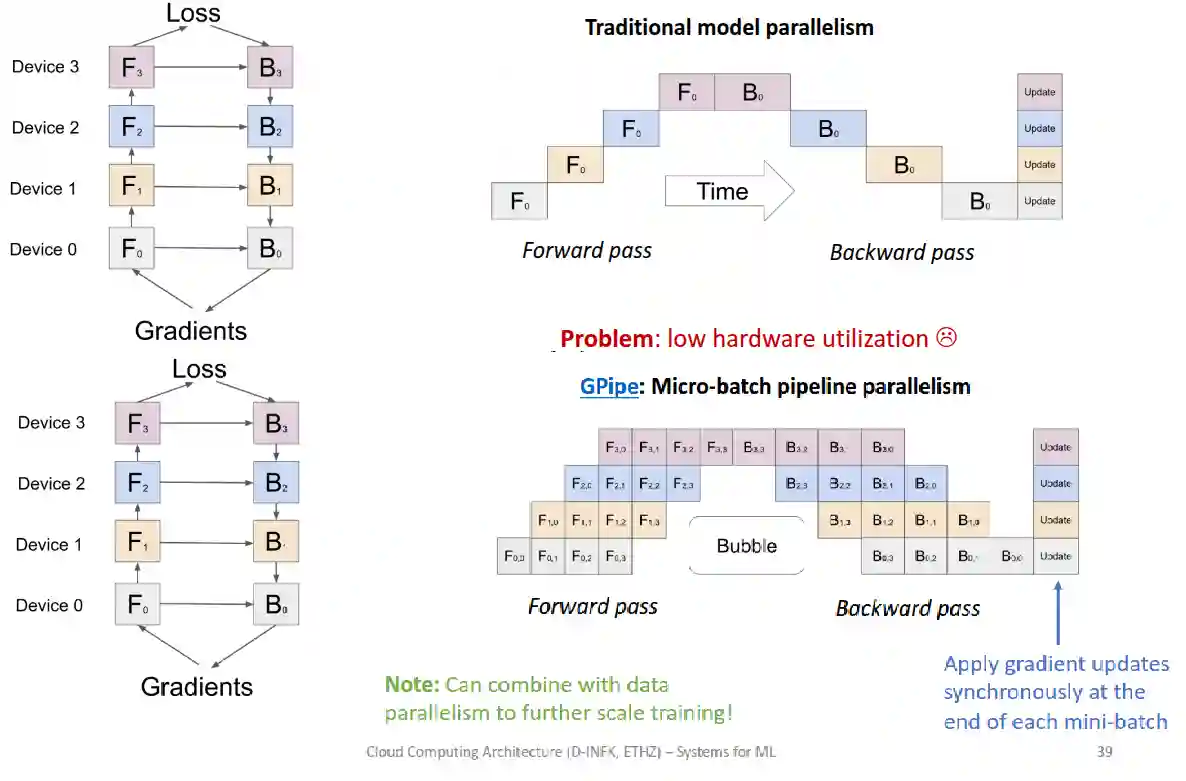
This form of parallelism is useful if you do not have a machine big enough to fit the whole model, but many machines, so you load the weights at each stage of the pipeline to compute the forward pass, pipelining makes the bubble time smaller, thus making the model more efficient.
Needs to communicate a lot less, only the end of one forward or backward, so it’s usually done across different nodes, since it’s more sparse.
Memory efficient Pipeline
Another example of a pipeline is (Kim et al. 2023), they introduce the one forward and one backward approach, in figure:

Image from the paper: An illustration of a 4-way 1F1B pipeline schedule with eight micro-batches. The memory pressure of each pipeline stage increases during the warmup phase, stays constant at the steady phase, and decreases within the cooldown phase. After the cooldown phase, parameters are updated with accumulated gradients of each micro-batch. A number in either forward or backward denotes the micro-batch index.
Where $\mu$ is the number of micro batches.
Data Parallelism
This is the easiest method for parallelism: you replicate the model many times as use that to train on different batches of data at the same times. But you can quickly observe if the model takes a lot of data then this is quite consuming in terms of memory.
Tensor Parallelism
Computing different parts of the tensor can be done in parallel, with different parts of the data. Even if a model can fit on a single GPU, it could benefit from tensor parallelism by splitting that part.
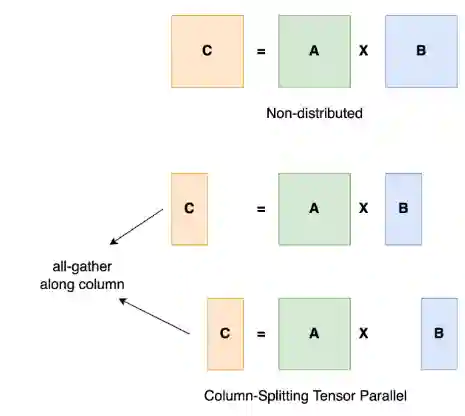
This is used within a node usually, because it needs to communicate a lot.
Sync or Async Training
Synchronous training is usually slow, there will be probably stragglers, for example see (Dean & Barroso 2013). Synchronous training: workers operate in lockstep to update the model weights at each iteration
- Asynchronous training: each worker independently updates model weights
- Synchronous training achieves better model quality, but lower throughput Accuracy vs. throughput trade-off. Useful metric: time to train to a target accuracy
Causes of Faults
Single failures can wipe out entire model parameters and waste lots of compute time. Restarting the training process is quite expensive. Common problem that make a node fail are:
- Hardware
- Misconfigurations
- Network problems
A common way to deal with this problem is using checkpointing If you use spot VMs with some GPUs and TPUs, the amount of failures is higher, difficult to ask a GPU in the cloud currently because everybody is asking for that currently.
Pipelined Checkpoints
Content of this section are introduced in ((Mohan et al. 2021)).
We want to checkpoint our current model parameters to some persistent storage. The problem is how can we balance the time needed to checkpoint and training? We don’t want too much overhead due to this part.
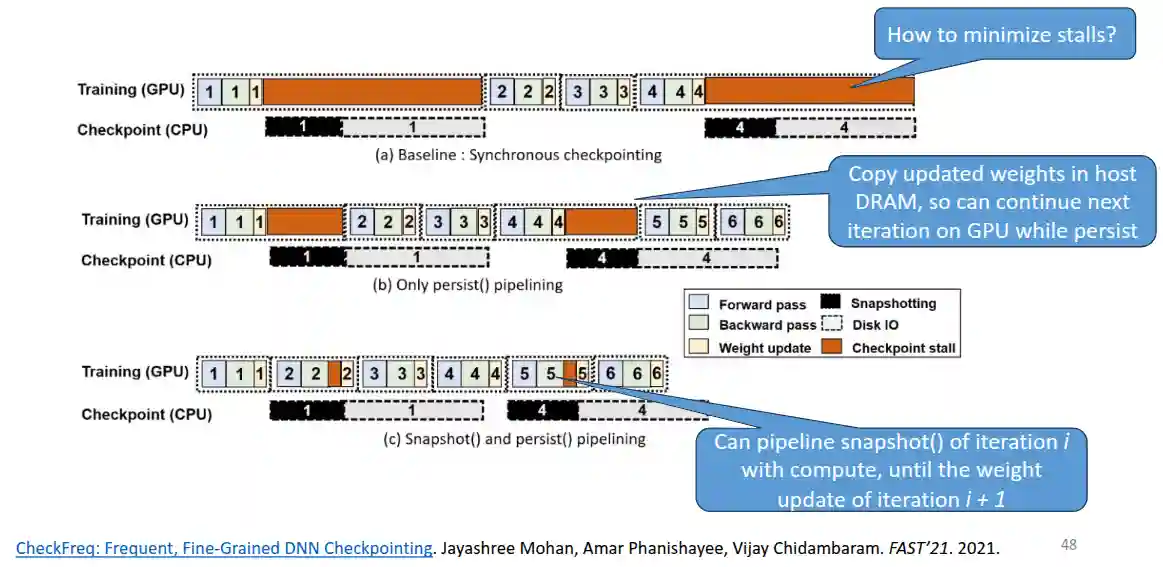
The idea is to start to copy to RAM after the first update has finished, but then start the computation for the next iteration immediately, and stall only for the remaining time, then disk I/O can be done in parallel.
There are two phases:
- Snapshot: copy the model parameters to RAM
- If spare space is available, do it in GPU, which is significantly faster.
- Persist: copy the model parameters from RAM to persistent storage The idea is that when we are copying to RAM or disk, we can continue to do computation and not stall. It uses some algorithm to determine the checkpointing frequency.
There is maximum one checkpointing operations at a time (maximum roll back is one checkpoint). The most important idea is that it does it in the middle of the checkpoints. If you checkpoint while the previous one is still running, you wait until previous checkpoint is finished. It saves two orders of magnitude compared to standard epoch checkpointing.
Also it saves epoch id and current number of processed items to provided inter-epoch state.
CheckFreq only maintains two checkpoints on disk at any given time; one completed checkpoint and the other in-flight.
3D Parallel
! Slides from Large Scale AI Engineering Course This is usually how it’s implemented for large scale training of models across clusters of GPUs, for very very big models. So there are lots of infrastructure working with these methods.
{kind=link}
Fully Sharded Data Parallel
This method reduces the memory usage for training by a lot, but makes implementation more difficult, and more communication overheads. So, it mostly depends on your memory availability regarding this part. At scale it’s not very useful, most of the people would use ZeRO-1 or ZeRO-2 (usually doesn’t give a good improvement over the first version). Here we are talking about Zero Redundancy Optimizer.
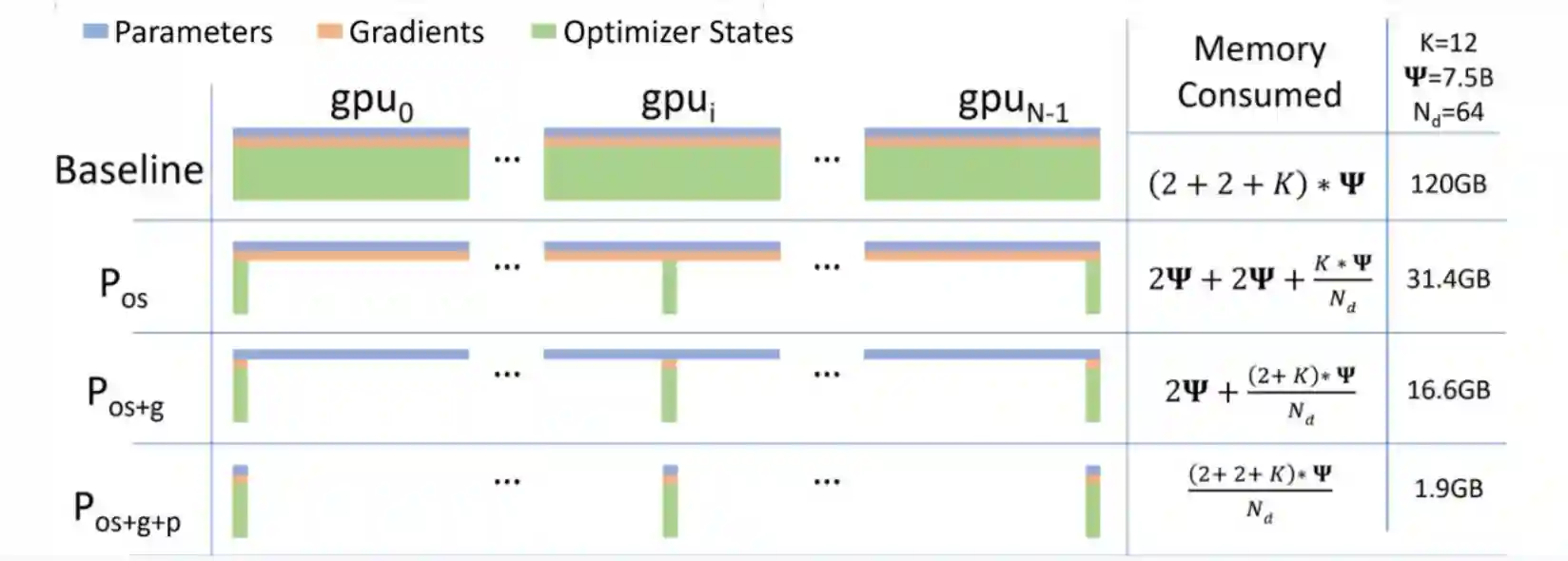
Weight for a Single Model Training
Training a model often requires much more memory compared to inference, let’s take an example to understand why.
- Training a 70B parameter model in 16-bit precision requires storage for:
- Model weights (FP16): 2 bytes per parameter
- Optimizer states (e.g. Adam):
- Two states (e.g. momentum & variance), each in 32-bit (4 bytes)
- Total memory per parameter:
2 + 4 + 4 = 10 bytes - Total memory requirement: $70 \times 10^9 \times 10 \text{ bytes} ; / ; 1024^3 \approx 652 \text{ GB}$
Model Inference
After we have trained the model, we want to optimize for response time.
Comparison between training and inference
Training: iterate through dataset, compute forward & backward pass on each batch of data to update model parameters.
- Care about high throughput and fast convergence to high accuracy
- Inference: compute forward pass on a (small) batch of data
- Care about low latency, high throughput and high accuracy
Inference location
We can mainly use two types of inference location:
- On the edge:
- Meaning it is running on your computer, locally, or on the device.
- It is probably the best option for privacy and latency.
- Yet it raises some challenges for energy consumption, and hardware types.
- On the cloud: - Meaning it is running on a remote server, in the cloud. - It is probably the best option for scalability and flexibility. - Yet it raises some challenges for privacy and latency. - e.g. OpenAI runs its model on Azure Cloud.
ML Compilers
They apply optimizations to the model, to make it run faster on the hardware on different devices. TVM from Tianqi Chen is an example of ML compiler, and it is open source. Goal: efficiently serve a trained model on different kinds of devices
- ML compiler applies multiple rounds of optimizations on computation graph, e.g., vectorization, loop tiling, operation fusion (one example is (Dao et al. 2022))
- Many ML compilers use ML to to some of the optimizations!
https://mlc.ai is a free course on ML optimizations for TVM.
Techniques for Cloud Inference
Clipper and Clockwork are some examples for Cloud inference.
- Batches
- Cache results (for example see KV cache in Optimizations for DNN)
- Compression and Model quantization
- Model selection based on latency and accuracy
- See an example: Model-less .
GPU resources allocation
We talked about dominance resource fairness in Cluster Management Policies. Here the authors of THEMIS propose the idea of finish time fairness, and minimize max finish time fairness across ML apps. That is the ration of exec time. AI jobs are often gang-scheduled (they do not advance if all jobs have not been scheduler first), and their performance is sensitive to tasks’ relative placement.
GPU under-utilization
There are some reasons why the GPUs are underutilized.
- Low batch sizes in ML inference
- Network congestion
- Input data scheduling Individual ML jobs do not make good use of GPUs, some are more memory intensive, others are CPU intensive.
GPU Sharing
- Temporal Colocation
- Spatial Colocation
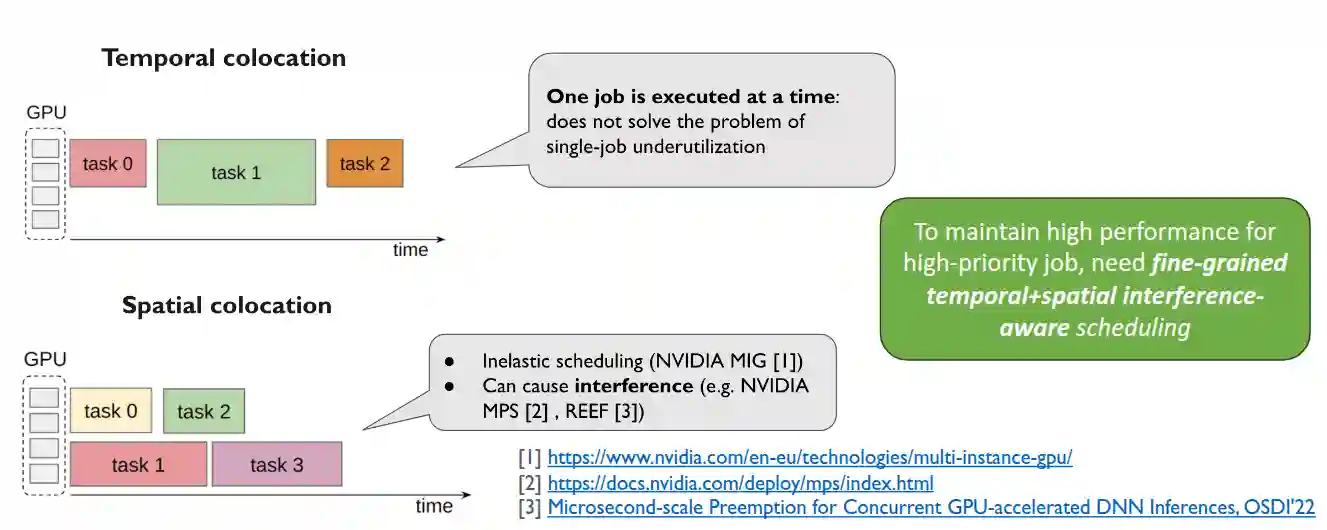
Orion is an example of this kind of interference aware scheduling.
Cost of Inference
It has been estimated some time ago that serving ChatGPT for a single day is about 700k dollars. Serving is very costly.
Batching
There are many difficulties in choosing the batching system. Should we stop at the longest token and return it in that way? What is the batch size we should start? So we need to have more effective batching systems!
We can continue to use after the end of the batching time! And a lot of memory is wasted in the KV cache part. This is partially solved by paged attention. For this we have three states, waiting, running, swapped.
References
[1] Huang et al. “GPipe: Efficient Training of Giant Neural Networks Using Pipeline Parallelism” Curran Associates, Inc. 2019
[2] Deng et al. “ImageNet: A Large-Scale Hierarchical Image Database” 2009 IEEE Conference on Computer Vision and Pattern Recognition 2009
[3] Bommasani et al. “On the Opportunities and Risks of Foundation Models” arXiv preprint arXiv:2108.07258 2022
[4] Dao et al. “FLASHATTENTION: Fast and Memory-Efficient Exact Attention with IO-awareness” Curran Associates Inc. 2022
[5] B{\"o}ther et al. “Modyn: Data-Centric Machine Learning Pipeline Orchestration” None 2025
[6] Kim et al. “BPipe: Memory-Balanced Pipeline Parallelism for Training Large Language Models” PMLR 2023
[7] Dean & Barroso “The Tail at Scale” Commun. ACM Vol. 56(2), pp. 74--80 2013
[8] Sculley et al. “Hidden Technical Debt in Machine Learning Systems” Curran Associates, Inc. 2015
[9] Mohan et al. “CheckFreq: Frequent, Fine-Grained DNN Checkpointing” 19th USENIX Conference on File and Storage Technologies 2021