A seconda dell’utilizzatore l’OS può essere molte cose, come solamente l’interfaccia se sei un programmatore, servizi (se sei un utente, ma gran parte dei servizi sono astratti e l’utente ne può anche essere a non-conoscenza).
Ma se sei un programmatore OS ti interessa capire le componenti principali dell’OS
- Slide componenti OS alto livello

Introduzione sui componenti (salto)
Questa parte la salto perché è una descrizione molto generale di cosa si occupa L’os verso drivers, processi, filesystem I/O, quindi non è molto importante
Gestione dei processi
All’interno del SO, il processo è rappresentato come un processo control block, che in linux è in sched, parte dello scheduler dei processi. Questo è importante perché per esempio per fare una fork, non faccio altro che duplicare questa struttura e settare bene i figli e genitori.
Questi sono solitamente messi un un process table o forse una lista per tenerne traccia.
-
Slide

nel parliamo in Processi e thread.
Gestione memoria principale e secondaria
Memoria Principale
È un array temporaneo(nel senso che non è mantenuto quando viene spento il PC.), indicizzato singolarmente a differenza del secondario, che è indicizzato a blocchi,
Una parte importante di questa parte è la gestione della memoria virtuale. Come allocare pagine di memoria, deallocarle e simili, ne parliamo in Paginazione e segmentazione
Memoria secondaria
La cosa buona è che questa memoria è permanente, efficienza (ordinare le richieste per non andare qui e lì quando si legge! minimizare tempi per seek) e partizionamento e reliability dei dischi sono problemi che interessano questa parte. Abbiamo parlato di raid in Memoria. e di nuovo in Devices OS.


I/O e filesystem
Principalmente per IO servono driver per interagire con specifici hardware, e un sistema di comunicazione che spesso sono buffer e cache.

Esiste un file system virtuale che mappa a tutto (quindi alcune cose non esistono realmente sul disco, potrebbe essere una astrazione utilizzata per esempio per comunicare con i devices.
Ci sono molti filesystem, che però posso gestire in modo differente la forma che hanno sul disco, Ed è per questo che possiamo dire che esistono dei filesystem diversi.
Anche i processi sono files, la cosa figa di questa astrazioen è che posso utilizzare gli stessi sistemi di protezione file per processi.
Struttura dei sistemi
Obiettivi di design dei SO (4)

- Efficienza
- Modularità
- Mantenibilità
- Espansibilità
Struttura del kernel
-
Slide riassuntiva
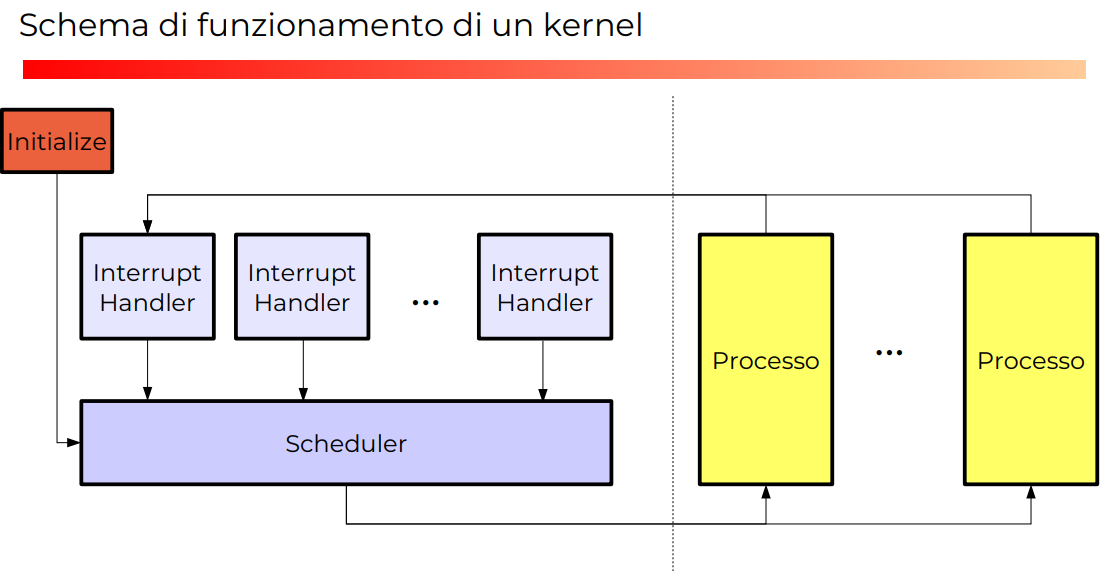
Il kernel è un unico processo, parte da un main che parte da un initialize in cui raccoglie tutte le risorse del sistema, fa partire tutti i device drivers e crea il PCB del primo processo, anche chiamato init, messo poi nella queue dello scheduler come spiegato in Scheduler. Fatta una volta non è mai più eseguito quel codice di init.
Lo stato kernel è la parte a sinistra dell’immagine, quella parte blu, tutto il giallo, a destra è lo stato user.
- Scheduler scegliere il processo da eseguire nello user space
- Il controllo è passato al processo user, che può fare traps (come fork) o fare I/O, a quel punto è rimesso a codice kernel.
Tipologie di struttura OS (2)
Solitamente i sistemi sono costruiti in due modi, sistemi semplici senza struttura, che praticamente c’è una prima versione, e poi viene ammassato roba senza struttura generale, fatti quando servono. Solitamente sono insieme di procedure che si chiamano fra di loro, e ben presto sono andate fuori dal loro ambito di interesse diciamo (fuori dal loro scope)
FreeDos and Unix
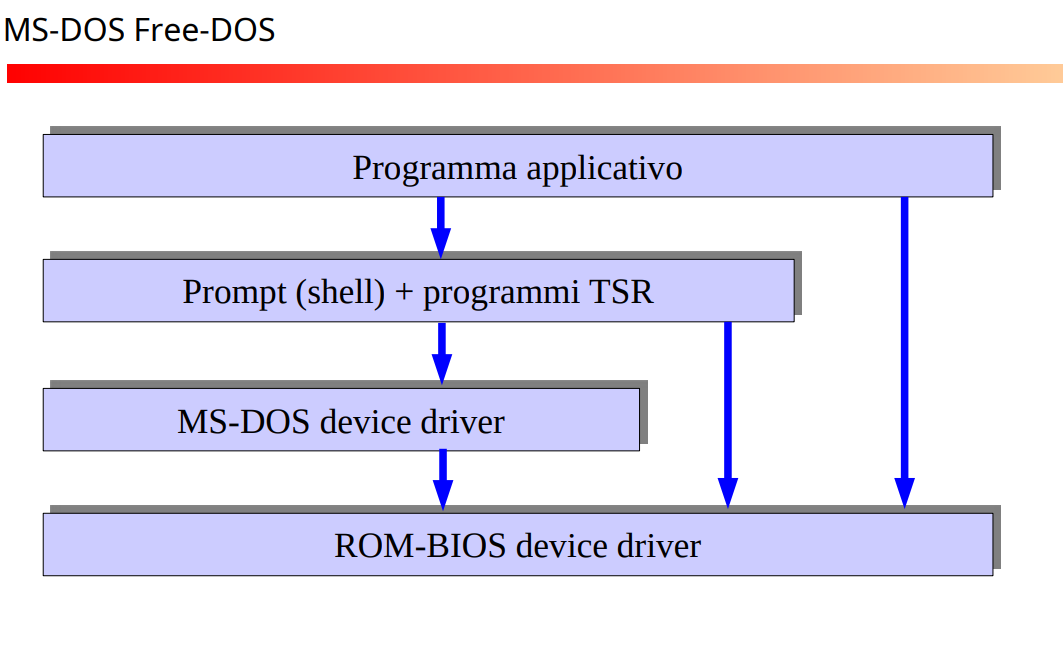
Un esempio è free-dos che è quanto installato su un computer senza sistema operativo.
In modo simile è MS-DOS, che è stato fatto per i primi personal computer, che non avevano un sistema kernel a livello hardware (non era quindi possibile fare queste protezioni).. In generale in questo ambiente un programma aveva accesso all’intera memoria, e poteva mandare in crash tutto.
-
Struttura Free-DOS
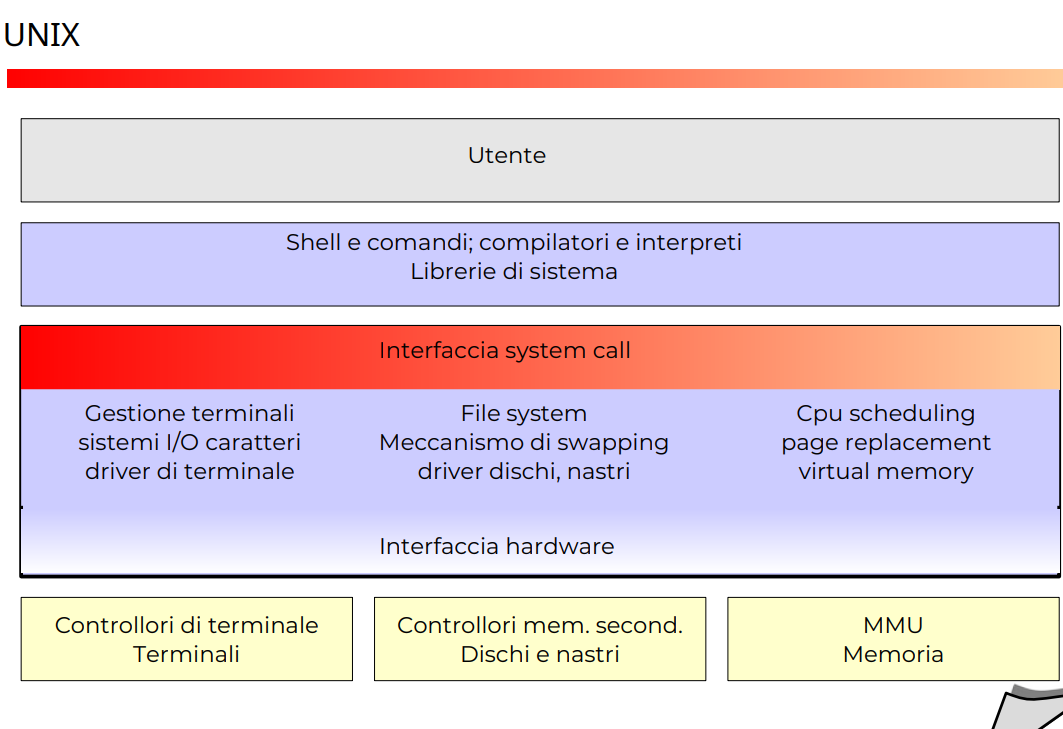
UNIX, è diviso diviso in due parti in kernel e programmi di sistemi, molto semplice, un kernel monolitico, un unico eseguibile, anche questo fu all’epoca limitato enormemente dal suo hardware, e una serie di programmi di sistema.
Dato che c’è una separazione, l’utente è separato dall’interfaccia dal codice kernel. Ma comunque il codice kernel resta vulnerabile, e potrebbe essere modificato e quindi attaccato, o cumunque vulnerabile a bug, anche colposi, distruttivi.
-
Struttura UNIX
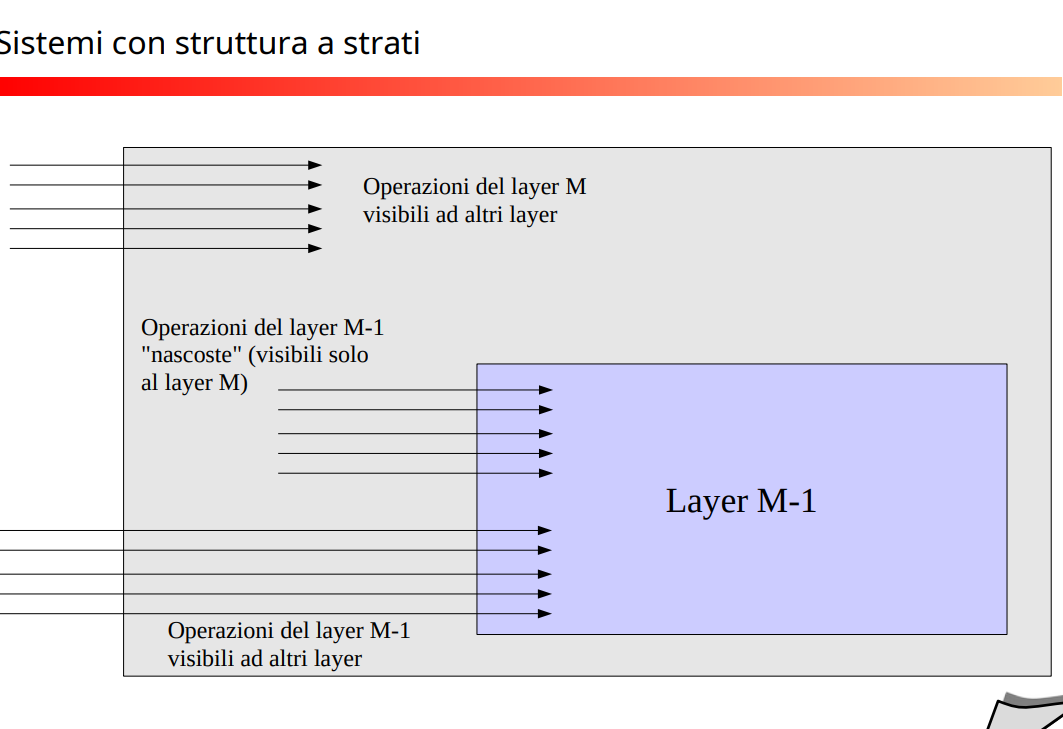
Stratificazione OS
La struttura a stati è più affidabile dell’altra e rende più facile la programmazione di tale sistema, utili, la logica è la stessa presentata in Architettura e livelli 1, 2, per la divisione a stack del sistema e dei vantaggi che si hanno con questo tipo di architettura.
-
Esemplificazione struttura a strati
-
Strutture proposte classiche (non fatte, non importanti)
Questi sono rimasti accademici

Ma nella pratica questi strati sono rimasti solamente a livello accademico, perché crea overhead anche se si guadagnerebbe in manutentibilità e estensibilità e gestione, quindi molto meno efficiente, inoltre non erano ben chiare le API fra strati. Oggi c’è una forma intermedia (non c’è esattamente la gestione a strati come abbiamo per Web, ma abbiamo una divisione per componenti e responsabilità delle componenti).
Politiche e meccanismi
La suddifivisione politiche e meccanismi è un pattern di software engineering che lo rende molto comodo da gestire.
Invece che una gestione a strati come per le reti, abbiamo una gestione di politiche e meccanismi ossia abbiamo qualcosa che decide cosa andare a fare e qualcosa che gestisce il come farla.
EG. un certo modo di memoria allocata per fare qualcosa, quindi indirizzare il sistema verso qualcosa, e MMU che attualmente implementa la decisione politica.
Esempio Microkernel o MINIX:
Il kernel è visto come il meccanismo quindi le parti di gestione e politica sono fuori dal kernel. Questo rende la struttura del SO molto mantenibile ed estendibile.
-
Slide

Esempio Mac OS ≤ 9 / Windows 9x:
Politiche e meccanismi sono messi tutti nel kernel, perché così imponevo un feeling unico al look and feel suo (obbligato tutti ad avere questi elementi grafici). Questo è un problema praticamente di mercato.
Questo era brutto perché la grafica può mandare in crash tutto il sistema. Anche se i nuovi sistemi non dovrebbero avere questo problema.
Categorizzazione dei Kernel
Monolitici
Il kernel è un unico programma. Si possono creare moduli che poi vengono caricati. Il problema principale di questo tipo di kernel è che se un modulo bugga crolla l’intero sistema. Un vantaggio è che è molto efficiente perché non deve passare ad astrazioni come per lo stack, basta fare una chiamata di funzione, tanto siamo nello stesso programma. Ed è altamente modularizzabile per poter attaccare nuove funzionalità.
In breve:
Vantaggi:
- Efficienza
- Modularità e mantenibilità (non devo ricompilare tutto, basta runtime).
Svantaggio:
-
Un modulo può mandare in crash tutto, perché è eseguito nello stesso spazio del kernel.
-
Slide
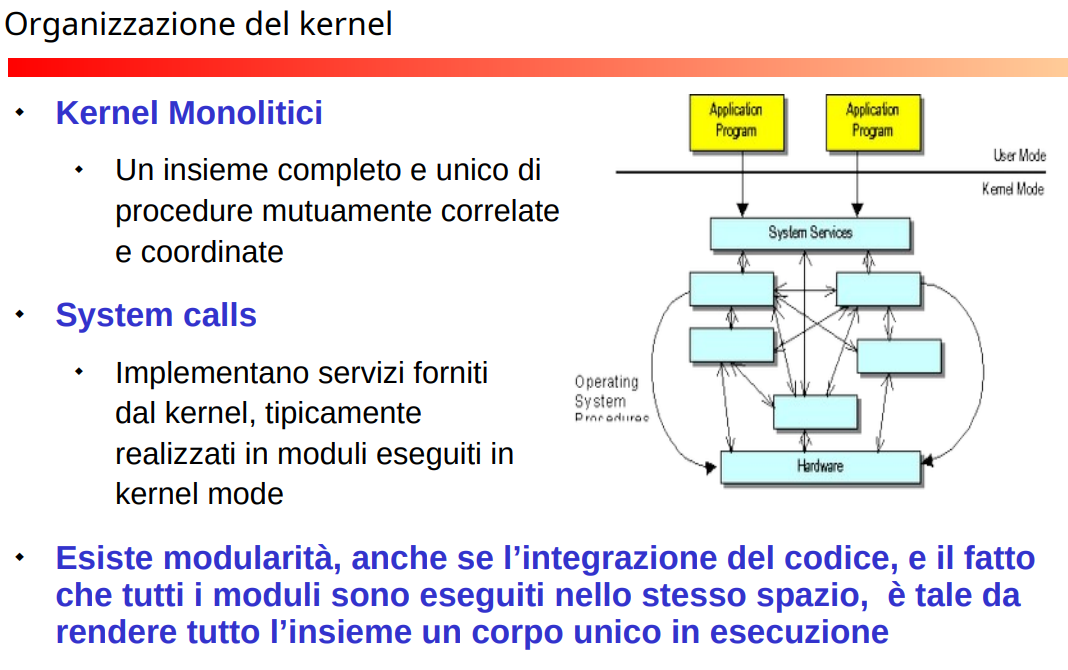
Esempi sono Linux o BSD.
Microkernel
L’obiettivo del microkernle è isolare solamente le funzionalità essenziali e tenere solo quelli (in un certo senso è quello che fa firecracker (Agache et al. 2020), ne parliamo in Cloud Computing Services), tutto il resto interagisce con esso con system call (un esempio è il filesystem che potrebbe essere fuori dal kernel, e avrebbe syscall leggermente diverse rispetto a quelle di linux, per aprire un file allora si chiederebbe a questo processo in user space, che poi fa altre richeste per kernel space)
Bisogna fare un messaggio, la syscall diventano Send! Che sarebbe unico modo per raggiungere il processo che offre il servizio che mi serve.
Vantaggi:
- Altissima modularità e mantenibilità del sistema e semplice da realizzare
- Assenza di danni di sistema, perché moduli e kernel sono eseguiti in spazio differente.
- Sicuro e affidabile per la divisione (non ho propagazione di errori e guasti)
- Molto portabile, che ho solo il microkernel.
Svantaggio:
-
Fortemente Inefficienza rispetto al monolitico, che devo fare message passing e comunicazione.
-
Slide di comparazione

Kernel Ibridi
Sono dei microkernel modificati, con qualcosa in più forse (aziende per pubblicizzarsi dicevano di avere microkernel, ma con un ibridone, mettendo le cose inefficienti del microkernel dentro il kernel).
-
Esempio windows
Ci sono diversi server, che fanno parte di un sottosistema d’ambiente che è in grado di emulare certe cose (sono nascoste le syscall reali del sistema così).
Il codice per un certo ambiente funziona anche nel sottosistema, un esempio è un WSL.
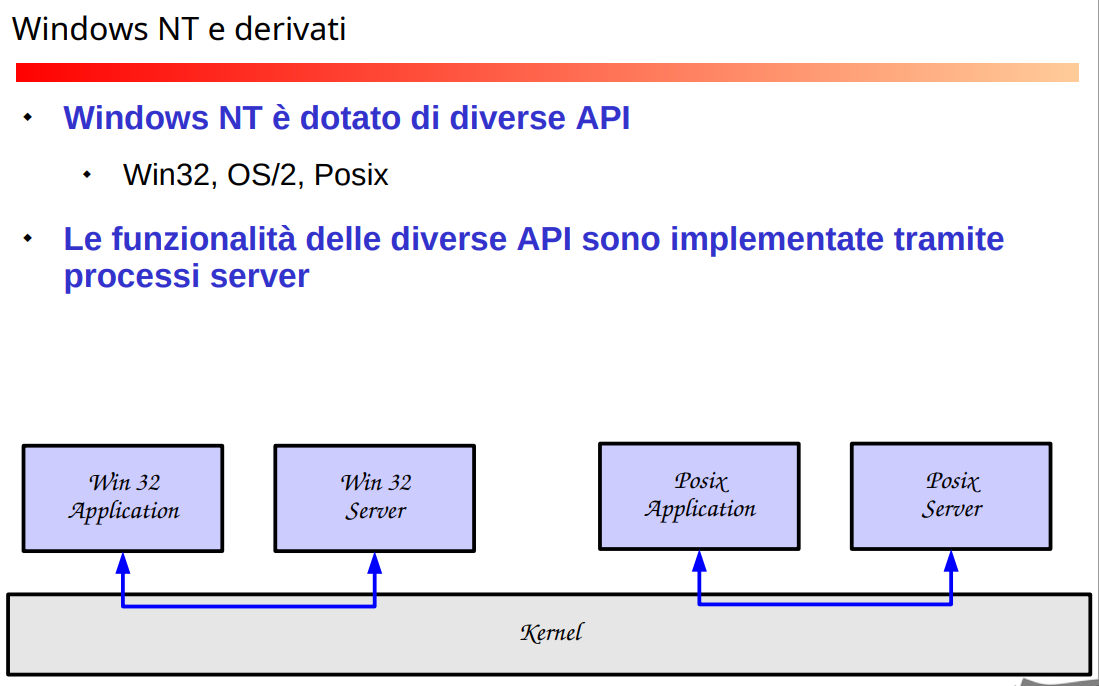
La parte grafica importante per fare i videogiochi, è dentro il kernel, questo ad esempio per MACOS, perché volevano imporre la grafica simile
Macchine virtuali
Vedi Virtual Machines.
References
[1] Agache et al. “Firecracker: Lightweight Virtualization for Serverless Applications” 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20) 2020