Robbins-Moro Algorithm
The Algorithm
the algorithm is very simple we do the following until convergence: set some learning rates that satisfy the Robbins Moro Conditions, choose a then update in the following way:
For example with , and they satisfy the condition (in practice we use a constant , but we lose the convergence guarantee by Robbins Moro). More generally, the Robbins-Moro conditions re:
- Then the algorithm is guaranteed to converge to the best answer.
One nice thing about this, is that we don't need gradients. But often we use gradient versions (stochastic gradient descent and similar), using auto-grad, see Backpropagation. But learning with gradients brings some drawbacks:
- We have no quantification of the uncertainty.
- We are usually overconfident in our predictions (adversarial examples, and poor generalization to domain shifts).
Convergence Proof
Given a dataset and parameters , we want to find such that the following holds:
And is our smooth and well-behaved function.
We updated our theta iteratively based on the above rule: . Then look at this:https://chatgpt.com/share/677e4cdb-4c60-8009-b57d-49ce8efeda5a (should be verified).

Bayesian Neural Networks
The Idea
The idea here is the same as the one applied to Bayesian neural networks: define a prior of the weights and likelihood and define a posterior over the weights. But the nature of the model makes it quite difficult, if not impossible to have a closed-form solution for the posterior.
A simple model
We want to predict the weights of a given model with some bounds on certainty about them. One thing is that we have always used linear models for this, but we can also use neural networks or more complex models. Usually, in some datasets also the variance changes with the input; this is called heteroskedastic noise. This justifies models in the following form:
where and are neural networks and are the weights of the neural network. We use neural networks to predict mean and variance. We use the function to ensure that the variance is always positive.
From a practical point of view, this machinery is quite good at estimating variance in regions where data is present (same thing in heteroskedastic settings!), while it is overconfident in zones without data, often collapsing the variance.
Map estimate for bayesian NN
Assume a prior and the above parametrization of the likelihood function, let's derive the posterior distribution, that is .
We notice that while in the Bayesian Linear Regression the normalization constant is disregarded, here it is dependent on the , so we need to consider it. We can pay higher variance cost to minimize the error in the quadratic term.
If we use the above model for Bayesian Modeling we derive the likelihood to be:
Here you observe that the likelihood is maximized by having high variance (plus penalty) or having correct estimates. Then adding the prior is just a regularizing term that corresponds to weight decay (a good exercise is to prove this part).
Prediction with Bayesian Neural Networks
We see that prediction is just averaging over the predictions of different networks sampled from the approximate distribution that we derived from the variational inference of the weights. Some formalization could help in clearing this out.
The variational is usually the approximation that is introducing the most errors.
Approximating with Gaussians
Training
Using the variational method, usually we parametrize with Gaussians. See Variational Inference. We usually use the ELBO to minimize the difference between the variational approximation and the true distribution.
Assuming a Gaussian prior, we can derive the ELBO as:
This is known as Bayes by backprop (2015), and is parameterized with a diagonal covariance Gaussian.
This is used to learn the covariance matrix and mean of the variational family. After, we can do inference in the following manner:
Inference
Intuitively, variational inference in Bayesian neural networks can be interpreted as averaging the predictions of multiple neural networks drawn according to the variational posterior
Unpacking uncertainties
We can un pack that uncertainty of the likelihood prediction using the classical aleatoric and epistemic uncertainties:
Where .
Bayes by Backprop
This section covers the idea of one quite influential paper (Blundell et al. 2015).
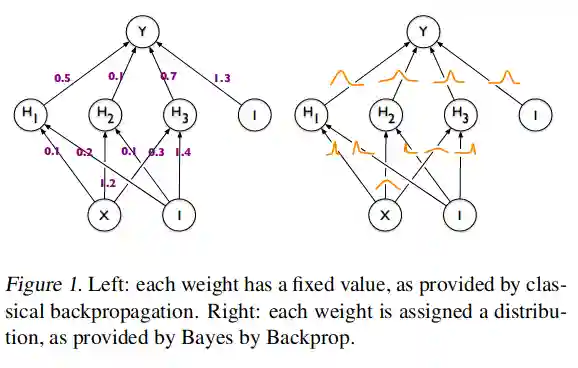
Image from the paper.This is the whole idea introduced in this document, but for historical reasons, it is due to treat it here. One of the main innovations introduced is the use of a derivative friendly method to compute an approximation for the variational lower bound principle.
In this work, they propose a generalization of the reparametrization trick, the same one used for training variational autoencoders (see Autoencoders)
In the paper they suppose to have a Gaussian prior for the network. This means that the update rules will be, assuming a reparametrization as:
For the mean and:
For the variance.
Disadvantages of Bayes by Backprop
- Increased Computation: BBB requires sampling from the posterior distribution of weights during both training and inference, which significantly increases computational overhead compared to standard neural networks.
- Slower Convergence: The need to approximate the posterior distribution can lead to slower convergence during training.
- Gradient Estimation: The gradients of the variational lower bound (ELBO) with respect to the parameters of the variational distribution can have high variance, making optimization challenging.
- Variational Approximation: BBB relies on variational inference to approximate the true posterior distribution. This approximation can be inaccurate, especially if the chosen variational family is not flexible enough to capture the true posterior.
With Laplace Approximation
We need to model the joint density as
If we marginalize over the parameters we get
The problem is often the Hessian, which could be unstable, or difficult to approximate. For this reason usually we use low-rank matrices, diagonal matrices, or other approximations.
Dropout as Variational Inference
Dropout and dropconnect can be seen as a special case of variational inference. It can been seen as if we are working with a probability distribution of different networks, which can be recalled as a special case of the one we have discussed above.
The Variational Family
With dropout, instead of working with a single network, we are working with many probabilistic networks. It can be interpreted as doing variational inference with the following variational family:
Where a mixture of Dirac deltas: with a certain probability we keep the weight, or set it to zero. Optimizing the network with dropout can be seen as optimizing the ELBO with respect of this variational family.
Inference with Dropout
One thing is using dropout during prediction to obtain uncertainty estimates. This is called Monte Carlo Dropout. The idea is very simple: keep the dropout during inference and sample from the network multiple times. The average of the predictions is the final prediction, and the variance is the uncertainty estimate.
Testing in Dropout models
When we add test time we need to rescale the inputs so that their activation strength is correctly resized.
Deep Ensembles
The Idea
We train different models from a bootstrapped dataset and then just average their prediction. This is the main idea of doing Ensembles.
We can also extend the probabilistic case to classification. In this case we just add a noise in the softmax layer to have some variability.
Inference
With this method we train different models on different data (maybe bootstrapped data, see Cross Validation and Model Selection). Then we just average the predictions of the different models. This is a very simple way to obtain uncertainty estimates, which allows to approximate the bayesian inference method.
Markov Chain Monte Carlo
The MCMC idea
We would like here to sample from the posterior distribution of the weights using MCMC (somewhat similar to the SGLD method), and then use the samples to make predictions. This is a very general method, but it's computationally expensive.
These methods explained in Monte Carlo Methods are exactly the same here, you can use these to sample from the posterior and then use the same tricks in #Inference (remember the Ergodic theorem) and #Unpacking uncertainties.
Often methods like SGLD or SG-HMC are used as they use stochastic gradients of a loss function, which can be obtained using automatic differentiation.
The key idea is just to sample values of the parameters and then use those values to make predictions.
Key Challenges
There are two main challenges with these methods:
- Storing the weights (usually to expensive).
- One way to circumvent this problem is to keep some snapshots or keeping some running averages (see next section).
- One idea is subsampling: we store some intermediate weights or predictions and use those for the final inference.
- Burn in period is too costly.
Running averages
Another idea is assuming a distribution over the weights (e.g. a Gaussian) and keeping the mean and variance of the weights. Then we can sample from this distribution. This is just the idea of SWA-Gaussians, presented (Maddox et al. 2019). This is a way not to store all the weights.
And:
Outlook: Other methods
Stein Variational Gradient Descent
This is called (SVGD) by Liu and Wang 2016. We want to approximate the posterior distribution with a set of particles and minimize the KL divergence between the true posterior and the approximated one. We consider an ensemble of models and we update them with the following update rule:
I have no idea why we use this update rule, but it should be minimizing a certain divergence between the two distributions. TODO: understand this part.
Calibration
What is Calibration?
Well calibrated models have a similar accuracy to the confidence of their predictions. This is a very important property for many applications, especially in medical fields. For example, if a model is well calibrated, if it is secure on a prediction, it can leave the burden from the doctors, who would just manually check the hard ones.
Expected Calibration Error
A well calibrated model's accuracy is the same as the probability, interpretable as a confidence score, of its prediction. Mathematically we say that a model is calibrated if
With the predictions of the model and its confidences and is the true label. So we would like to have
Usually it's quite difficult to have the exact estimates, so we do some heuristics to calculate this value. We divide the model's predictions into bins based on the confidence score. Let's say we defide all the space in into bins. Then we say that the empirical accuracy score in the bin is
where is the number of samples in the bin and is the indicator function. Then we can calculate the expected calibration error as And the confidence score is
Then we can calculate the expected calibration error (ECE) as
Sometimes we are also interested in the Maximum Calibration Error defined as
Reliability Diagrams
We group the predictions of the model into bins based on their confidence. Then we plot the average confidence score against the accuracy of the model in that bin. If the model is well calibrated, this plot should be a diagonal line.

Example from a paper
Techniques for improving calibration
Temperature Scaling
There are many techniques to improve calibration. One of the most used is temperature scaling. This is just a scaling of the logits of the model.
Platt Scaling
Another technique is Platt scaling. This is a logistic regression on the model's output logits, interpretable as confidence scores.
References
[1] Blundell et al. “Weight Uncertainty in Neural Networks” arXiv preprint arXiv:1505.05424 2015
[2] Maddox et al. “A Simple Baseline for Bayesian Uncertainty in Deep Learning” arXiv preprint arXiv:1902.02476 2019