The idea of ensemble methods goes back to Sir Francis Galton. In 787, he noted that although not every single person got the right value, the average estimate of a crowd of people predicted quite well.
The main idea of ensemble methods is to combine relatively weak classifiers into a highly accurate predictor.
The motivation for boosting was a procedure that combines the outputs of many “weak” classifiers to produce a powerful “committee.”
In Buhmann's optinion, somehow this is also why democracy works well. But it won't work anymore if too many individuals are correlated with each other.
Some properties of Ensembles
Variance of Ensembles
Consider a set of estimators and their average
Then the bias of the average is the same as the average of the biases, which implies if originally the estimators are unbiased, then the average is unbiased too!
But if we look at the variance, then we see that the variance decreases if the estimators are uncorrelated with each other! This leads to more correct estimates.
In reality, the predictors are often correlated, which is why the variance of the ensemble is not as low as we would like.
Advantages of Ensembles
Usually weak classifiers are easy to train (the only thing we need is to be better than random).
Data randomization in the spirit of Bootstrap captures statistical dependencies between alternative hypotheses. -> The classifier ensemble encodes uncertainty intervals in the hypothesis class (output space).
Bagging
In this whole section we will assume that the classifiers output . The idea of bagging (Breiman 1996) is producing a diverse set of classifiers using Bootstrapped samples (or other methods to induce diversity in the classifiers). And then keep the prediction as the average of the predicted values by each classifier. This technique is known also as committee methods.
Bagging Classifiers
The basic idea of this method is quite easy, and builds upon bootstrap, introduced in Cross Validation and Model Selection. Set the number of classifiers to train. Then do the following: For times:
- Sample with replacement the training set (this is the bootstrap part)
- Train a classifier on this sample
- Output the sum the predictions of the classifiers and take the sign as the classification result. This setting only works for the binary classification problem, and it is slightly biased in case the number of the classifiers is odd.
Compare and Bag
This method has a very similar idea to the previous one. But are training two different ensembles and selecting based on the performance of the validation set.

Random Forests
The Idea
This method leverages on Decision Trees to build a forest of them. The idea is to create enough different classifiers so that we can build upon the observation on the variance of ensembles.

Diversifying the models
Ways to diversify the trees are:
- Train them on different bootstrapped samples
- At each split, just consider a subset of features (Typically the square root).
- Use different splitting criteria (Gini index, Entropy, Misclassification).
There could be other methods that we are not considering here.
Boosting
The main difference between boosting and bagging methods is that here the classifiers are trained in sequence.
AdaBoost algorithm
The main idea of AdaBoost, which has been a breakthrough in the field of statistical learning, is to train a sequence of classifiers, each of which focuses on the examples that the previous classifiers have misclassified. If a sample has been misclassified in a previous attempt, it will have a higher weight in the next classifier. It is implemented in the following way:

Curious choices are for the and how we scaled the weights. These will be discussed in the next section.
A philosophical similarity
Adaboost is just a collection of simple algorithmic steps which could be interpreted as some optimization objective in the larger scheme of things. This has some commonalities with some philosophical view from Wolphram in (Wolfram 2002).
Forward Stagewise Additive Modeling
Forward Stagewise additive modeling focus on building a sequence of classifiers, each of which try to solve for the residual of the previous ones. The algorithm is the following:
- Initialize
- For :
- Compute the residuals
- Fit a classifier to the residuals , call it
- Choose a step size by solving the optimization problem
- The above three steps can be summarized as finding
- Update the model are also called basis functions. In this setting, they are the classifiers interesting to us.
Adaboost's energy function
We can prove that Adaboost is just a special case of these models with the following Loss function:
This has some slight resemblance to Log Linear Models.
Let's see why. The predictions for the AdaBoost model for a certain training sample
We substituted . as this value is constant for state . We now observe that the energy (score) for this value is
If take the gradient with respect to and set it to zero, we find that the value of is
Where error is defined as
Now we see how we update the weights:
Then using the observation that
We rewrite the above as
We note that the term is a constant, this can be dropped when calculating the error as it is insignificant for the weighted average. Now we have Adaboost's weight update rule in the classification setting.
Is the exponential a Good Loss?
From(Bishop 2006):
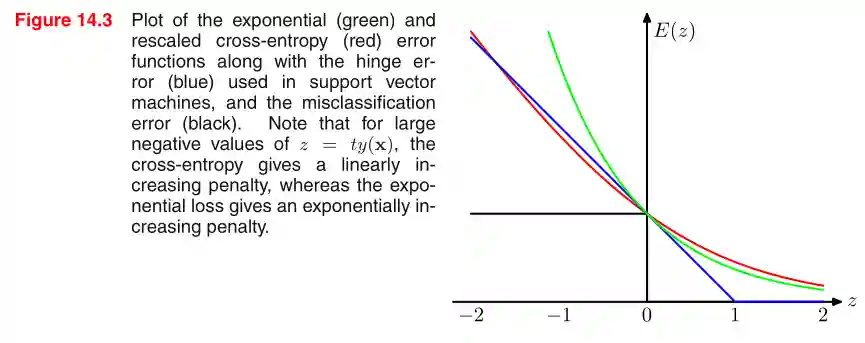 We observe that the misclassification error for the exponential loss grows exponentially for negatives, which could be sign of a high sensitivity to outliers.
Another note on the exponential loss: it cannot be interpreted as log likelihood of some well defined probability distribution.
We observe that the misclassification error for the exponential loss grows exponentially for negatives, which could be sign of a high sensitivity to outliers.
Another note on the exponential loss: it cannot be interpreted as log likelihood of some well defined probability distribution.
Another drawback of the exponential loss compared to a cross-entropy loss is the extension to multi-class classification: while with cross entropy it's easy, with the exponential loss there is no straightforward manner to extend it to multi-class classification.
Recall that the cross entropy loss is:
But in the case of The loss becomes:
Used for Linear Classification, as the underlying probability is different.
And the hinge loss is:
Used from Support Vector Machines
Adaboost and Logistic Regression
What does AdaBoost estimate and how well is it being estimated? it turns out that AdaBoost is estimating the posterior probability of a sample having probability 1 using logistic regression each time! We can show that the minimizer of the expected energy is as follows:
The proof is quite straightforward:
Which allows us to rewrite the probability of the class 1 to be:
This is also close to the sigmoid function! Remember that this is why in Logistic Regression, Sigmoid is a good choice for the loss function.
References
[1] Wolfram “A New Kind of Science” Wolfram Media 2002
[2] Bishop “Pattern Recognition and Machine Learning” Springer 2006