There is huge literature on planning. We will attack this problem from the view of probabilistic artificial intelligence. In this case we focus on continuous, fully observed with non-linear transitions, an environment often used for robotics. It’s called Model Predictive Control (MPC).
\[...\]Moreover, modeling uncertainty in our model of the environment can be extremely useful in deciding where to explore. Learning a model can therefore help to dramatically reduce the sample complexity over model-free techniques.
A general algorithm usually follows this outline:
- Initialize policy
- For some episodes:
- Collect data following a certain policy
- Learn a model $f$ of the world and the rewards $r$.
- Update the policy using the learned model.
We can categorize the challenges into three main buckets:
- How to develop policies given some model of the world
- How to infer the model of the world
- How to balance exploitation against exploration (the classical problem).
Known Dynamics Case
We try develop methods to scale to large MDPs. in this setting we have a deterministic model of the world, and would like to develop a policy that returns the maximum reward. This problem has been heavily studied in a field named optimal control.
Setting of the problem
We have a deterministic model (often used for optimal control):
$$ x_{t + 1} = f(x_{t}, a_{t}) $$$$ \max_{a_{0}: \infty} \sum_{t=0}^{\infty} \gamma^{t} r(x_{t}, a_{t}) $$But his is often not feasible to compute. This is exactly the same as the ones we have explored in RL Function Approximation, but here we explicitly model the transition probabilities, and the time horizon was equal to $1$.
Finite horizon version
$$ \max_{a_{0}: H} \sum_{t=0}^{H} \gamma^{t}r(x_{t}, a_{t}) $$$$ J_{H}(a_{t:t + H - 1}) = \sum_{\tau = t}^{t + H - 1} \gamma^{\tau - t}r(x_{\tau}, a_{\tau}) $$Where $x_{\tau}$ is the state we reached after executing the first $\tau - 1$ actions. The objective is then finding the actions that minimize that cost. If this cost is continuous and differentiable, then we can use gradient descent methods with Backpropagation. This problem is calle model predictive control.
If it is not differentiable, we can use Monte Carlo Methods (AlphaZero can be seen as an advanced version of these methods). These are called random shooting methods.
One clear drawback of finite horizon setting is when we have sparse rewards. If in the whole horizon the model doesn’t see any action that brings any reward, then it cannot learn anything. This is quite intuitive. One possible solution is adding a value estimate to the last reached state, (Krause calls this method return to go).
$$ J_{H}(a_{t:t + H - 1}) = \underbrace{\sum_{\tau = t}^{t + H - 1} \gamma^{\tau - t}r(x_{\tau}, a_{\tau})}_{\text{Short Term}} + \underbrace{\gamma^{H} V(x_{t + H})}_{\text{Long Term}} $$If $H = 1$, then we have the greedy policy with respect to the value function, we have studied many of these settings in Tabular Reinforcement Learning and RL Function Approximation.
The stochastic Case
$$ J_{H}(a_{t:t + H - 1}) = \mathop{\mathbb{E}}_{x_{t + 1: t+H}} \left[ \sum_{\tau = t}^{t + H - 1} \gamma^{\tau - t}r(x_{\tau}, a_{\tau}) + \gamma^{H} V(x_{t + H}) \mid a_{t: t+ H - 1}, f\right] $$A common approach is using monte carlo trajectory sampling. This is usually a high dimensional integral.
We have the same problem of states that depend on the actions. So we can use the score trick or reparameterization trick, as before. A common approach is the latter with the Gaussian policy. Applying this trick, we can estimate the expectation in this way:
$$ J_{H}(a_{t:t + H - 1}) = \frac{1}{N}\sum_{i=1}^{N} \left[ \sum_{\tau = t}^{t + H - 1} \gamma^{\tau - t}r(x_{\tau}^{(i)}, a_{\tau}^{(i)}) + \gamma^{H} V(x_{t + H}^{(i)}) \right] $$Where $x_{\tau}$ is derived from the stochastic model instead with the underlying stochastic transition function. (Sample from normal Gaussian and then reparameterize). (See slides, this syntax has been written in a slightly different manner).
Control Loops
The problem with the current approach is that solving this optimization problem at every step could be quite expensive! This problem is called closed control loop. This leads to parameterized $q$ functions in an attempt to make things faster. We parameterize a policy $a_{t} = \pi(x_{t}, \theta)$, which brings us to offline methods for faster online evaluation. This is called open control loop.
$$ J_{\mu, H}(\varphi;\theta) = \mathop{\mathbb{E}}_{x_{0} \sim \mu, x_{1:H} \mid \pi_{\varphi}, f} \left[ \sum_{\tau = 0}^{H - 1} \gamma^{\tau}r_{\tau} + \gamma^{H} Q(x_{H}, \pi(x_{H}, \theta)) \mid \theta \right] $$Where $\mu$ explores all states with probability $> 0$. One nice thing about this approach is that with $H = 0$ it corresponds with the DDPG algorithm.
$$ \pi^{*}(x) = \arg\max_{a} Q^{*}(x, a; \theta) $$The two methods are quite similar if viewed from this point of view.
Unknown Dynamics
In this setting, we don’t know the transition model $f$ neither the reward function $r$. We will use the same idea in Tabular Reinforcement Learning, we will attempt to learn the transition and reward model based on some rollouts of the current policy.
The main idea
$$ x_{t + 1} \sim f(x_{t}, a_{t},; \psi) $$The case of the reward function can be done in exactly the same manner.
Using Conditional Gaussians
$$ x_{t + 1} \sim \mathcal{N}(\mu(x_{t}, a_{t}; \psi), \sigma(x_{t}, a_{t}; \psi)) $$And one nice thing we only need to use $n (n + 1) / 2$ parameters. We note that if the variance is 0, then it reduces to a deterministic setting.
Main Drawbacks
If we set some finite horizon $H > 1$ the problem with the approximations is that the errors compound. The planning algorithm then runs on probably erroneous models (or uses the noise as information), which brings poor performance. This is also often why using point estimates is a bad idea in control settings. One way to address this problem is to capture epistemic and aleatoric error and try to model them.
Greedy Planning
Separating Errors
The epistemic error is the uncertainty in $P(f \mid D)$ while the aleatoric is the uncertainty of the point given the model $p(x_{t + 1} \mid f, x_{t}, a_{t})$ and is usually irreducible and inherent of the problem we are trying to solve and can be attributed to uncertainty of the transitions in the underlying Markov Process.
Then, we would like to focus on the epistemic uncertainty, i.e. the error that we have some control over. We can use the same idea of sampling repeatedly from the model and then taking the mean of the rewards. (Somewhat akin to Thompsom Sampling explored in Bayesian Optimization).
The PILCO algorithm
This is somewhat similar to an algorithm called probabilistic inference for learning control (PILCO).
- Define empty dataset and prior $P(f) = P(f \mid \left\{ \right\})$
- Iterate:
- Find $\pi$ such that it maximizes $$ \arg\max_{a_{t:t+H - 1}} \mathop{\mathbb{E}}_{f \sim P(f \mid D)} \left[ \sum_{\tau = 0}^{H - 1} \gamma^{\tau}r_{\tau}(x_{\tau}, a_{\tau}) + \gamma^{H} Q(x_{H}, \pi(x_{H}, \theta)) \mid \theta \right] $$
- Collect a dataset of rollouts $D = \left\{ (x_{1}, a_{1}, r_{1}, x_{i + 1})_{i} \right\}$ using this policy
- Update the prior $P(f \mid D)$
The PETS algorithm is one example of these methods.
Here $f$ is a model of the world which tells us how the state updates after a certain action is made: $x_{t + 1} = f(x_{t}, a_{t}; \psi)$, sometimes we parametrize with Gaussians, especially in continuous settings.
Exploration
Reinforcement Learning can be seen as an expansion over Bayesian Optimization: we add actions and world models to the states (inputs) and rewards (outputs). This motivates the usage of some algorithms developed in that setting in the new one. One of the problems we had in Bayesian Optimization is the exploration and exploration trade-off. In this section, we will discuss about that problem in this setting.
Some exploration techniques
Gaussian Dithering
This is a simple idea: we add some noise to the actions. This idea has been discussed before too. See Bayesian Optimization.
Thompson Sampling
This is exactly the same idea in Bayesian Optimization: The algorithm goes as follows:
- Initialize the empty dataset $\mathcal{D} = \varnothing$ and the prior $p(f) = p(f \mid \mathcal{D})$
- For some episodes do:
- Sample a model $f \sim p(f \mid \mathcal{D})$
- Find the policy that maximizes the expected reward under this model $\max_{\pi} J_{H}(\pi; f)$.
- Execute this policy and collect the data $\mathcal{D}$
- Update the prior $p(f \mid \mathcal{D})$
Optimistic Exploration
The Idea
$$ f_{i}(x, a) \in \mathcal{C}_{i} = \left[ \mu_{i}(x, a) - \beta_{i}\sigma_{i}(x, a), \mu_{i}(x, a) + \beta_{i}\sigma_{i}(x, a) \right] $$Let us consider a set $\mathcal{M}(\mathcal{D})$ of plausible models given some data $\mathcal{D}$. Optimistic exploration would then optimize for the most advantageous model among all models that are plausible given the seen data.
Then the set of plausible models is $\mathcal{M}(\mathcal{D}) = \left\{ f_{i} \mid i = 1, \ldots, d \right\}$. Such that that function is in $\mathcal{C}_{i}$
The algorithm goes as follows:
- Initialize the empty dataset $\mathcal{D} = \varnothing$ and the prior $p(f) = p(f \mid \mathcal{D})$
- For some episodes do:
- Find the policy that maximizes the expected reward under the most optimistic model.$$ \max_{\pi} \max_{f \in \mathcal{M}(\mathcal{D})} J_{H}(\pi; f) $$
- Execute this policy and collect the data $\mathcal{D}$
- Update the prior $p(f \mid \mathcal{D})$
H-UCRL
$$ \pi_{t + 1} = \arg\max_{\pi} \max_{\eta(\cdot) \in [-1, 1]^{d}} J_{H}(\pi; \hat{f}_{t}) $$$$ \hat{f}_{t}(x, a) = \mu_{t}(x, a) + \beta_{t}\eta_{t}\sigma_{t}(x, a) $$Where the new variable $\eta \in [-1, 1]$.
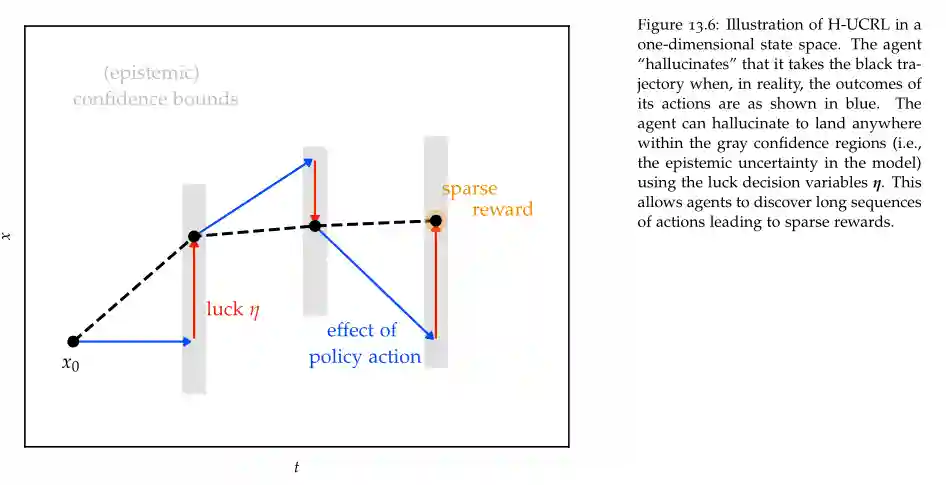 Illustration of H-UCRL from the Textbook.
Illustration of H-UCRL from the Textbook.
Safe Exploration
TODO
This part also links to Hübotter’s idea on transductive learning, see Active Learning.
Basic formulation
We define a constrained formulation with some variable $\delta$ and say that the function is safe (constrained) if it satisfies the following:
$$ \begin{align} \max_{\pi} &J_{\mu}(\pi, f) = \mathop{\mathbb{E}}_{x_{0} \sim \mu, x_{1:H} \mid \pi, f} \left[ \sum_{\tau = 0}^{H - 1} \gamma^{\tau}r_{\tau} + \gamma^{H} Q(x_{H}, \pi(x_{H}, \theta)) \mid \theta \right] \\ \text{Subject to } & J_{\mu}^{c}(\pi, f) = \mathop{\mathbb{E}}_{x_{0} \sim \mu, x_{1:H} \mid \pi, f} \left[ \sum_{\tau = 0}^{H - 1} \gamma^{\tau}c(x_{\tau}) \right] \leq \delta \end{align} $$One usually optimizes for the Lagrangian, see Lagrange Multipliers.
Optimistic and Pessimistic
We have already encountered some optimistic approaches in RL Function Approximation. Here we will introduce a simple idea of being pessimistic about the safety contraints: TODO.